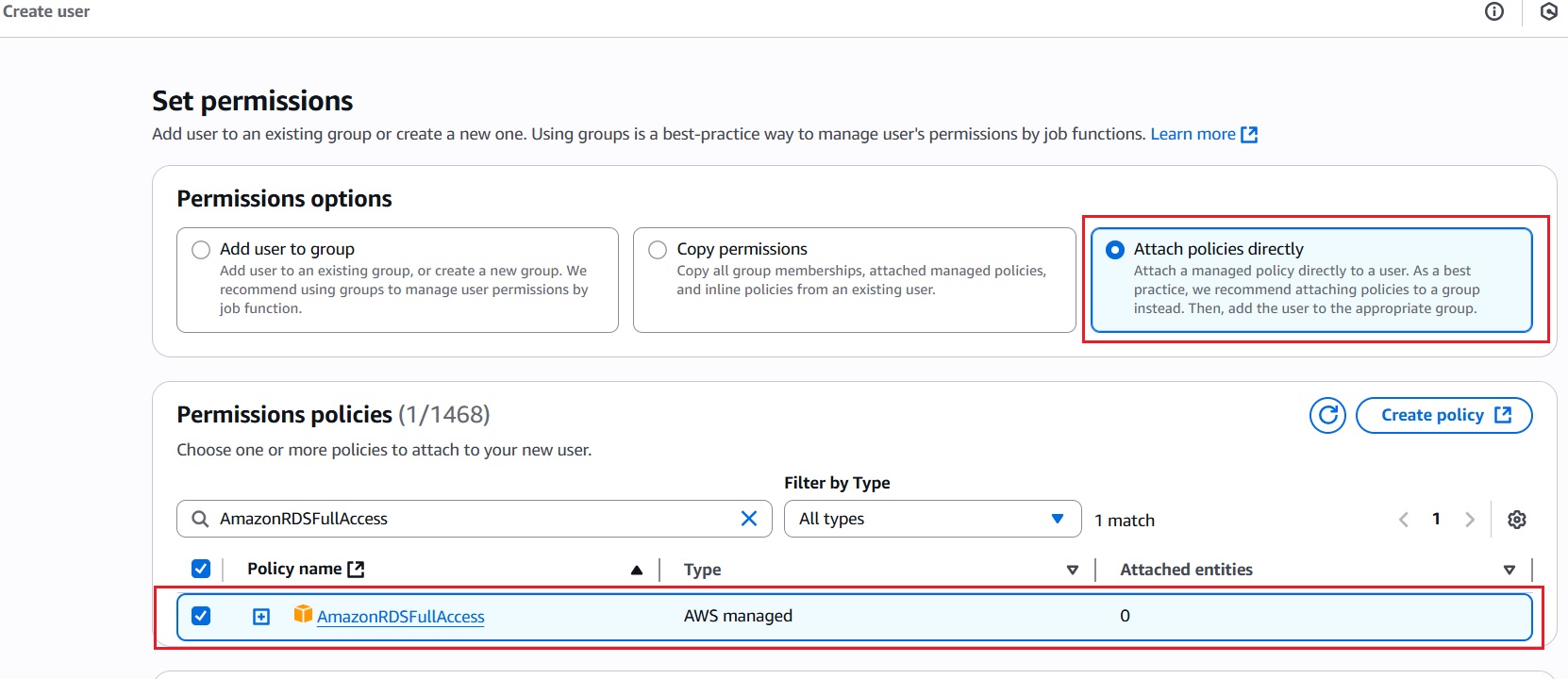
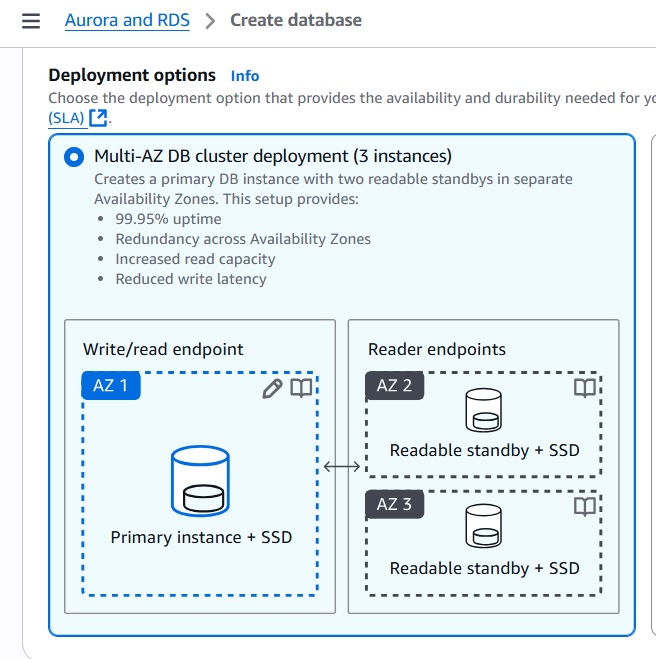
Thanks bạn vì đã có ý kiến về bài giảng. Đúng, bạn đã hiểu đúng. Edge Location không ảnh hưởng đến tốc độ xử lý trên máy chủ web server. Mục đích chính của Edge Location là giảm thời gian độ trễ (latency) trong việc truy cập dữ liệu từ máy tính người dùng đến các máy chủ web servers. Khi người dùng yêu cầu truy cập dữ liệu, Edge Location sẽ cung cấp dữ liệu từ các điểm gần nhất với người dùng cuối, giúp giảm thời gian mà dữ liệu phải đi qua qua mạng và tới đích. Việc này giúp cải thiện trải nghiệm người dùng bằng cách giảm độ trễ và tăng tốc độ truy cập.
Và trong bài giảng mình cũng nói rõ là Edge Location giúp giảm thời gian độ trễ (latency). Tuy nhiên trong slide thì có để câu: “Giúp tăng tốc độ trong việc xử lý thông tin cho hệ thống AWS”. Có thể gây hiểu lầm chút nhé!
4. Hỏi: Hi anh! bài lab cuối, lab260 (5 phần), khi tạo cloudformation, báo faile, mình thử 2 account khác gõ cloud9 cũng hiện ra thông báo không thể truy cập coud9. vậy thực hiện bài lab cuối thể nào?

Trả lời:
Hello Vinh! Mình đã update bài Lab 260 (5 phần) “Sử dụng ECS Fargate, RDS, Parameter Store, và Secrets Manager để cấu hình một WordPress Application” với file Yaml Cloudformation và file PDF hướng dẫn để tạo môi trường hạ tầng cho bài lab, không còn sử dụng Cloud 9 nữa, mà thay vào đó hạ tầng hệ thống sẽ sử dụng một EC2 AWS Linux cho việc Pull và Push Docker image lên ECR Repo. Vậy bạn có thể làm bài lab nhé.
5. Hỏi: Hi anh! cho mình hỏi bài thực hành 225, phút 6:25, chỗ này đăng nhập user IAM phải có account ID, trong bài không thấy account id của user db-1, nhập account id theo như hình trên video 959764676190, user db-1, pass 6!AY36^5h1 không vào được ( báo sai user /pass). (Ý mình muốn hỏi là không thấy link đăng nhập cho user db-1, trong đó có account id)?
Trả lời:
Hello Vinh, Mỗi một 1 AWS user có 1 Console sign-in link nhé! Do đó bạn cần làm như sau: Để lấy link đăng nhập vào AWS console của user db-1, Vinh vào dịch vụ IAM> Users > click vào user db-1 > Click vào Tab Security credentials > Copy Console sign-in link của riêng user này. Sau đó mở trình duyệt web và paste link vào, nhập user và password như mình đã hướng dẫn trong video bài học nhé.
6. Hỏi: Cho mình hỏi chỗ thực hành lab 191 aws config, mình có vào thực hành theo video, xong kết thúc. aws config này muốn tắt, hoặc disable thì vào đâu tắt nó, do vào chỗ bill thấy nó phát sinh 0.34 USD (vào aws config không thấy chỗ nào tắt dịch vụ này hoặc xóa nó )?



Cách AWS Config tính phí
AWS Config tính phí dựa trên ba yếu tố chính:
Số lượng configuration items: Mỗi khi có thay đổi cấu hình tài nguyên, một configuration item được ghi lại.
Số lần đánh giá của các Config rules: Mỗi lần một rule được đánh giá (evaluation), bạn sẽ bị tính phí.
Số lần đánh giá của conformance packs: Tương tự như trên, nhưng áp dụng cho các gói quy tắc.
Cụ thể, theo thông tin từ trang AWS Config Pricing:Amazon Web Services, Inc.
$0.003 cho mỗi configuration item được ghi lại.
$0.001 cho mỗi lần đánh giá của một Config rule.vantage.sh
$0.001 cho mỗi lần đánh giá của một conformance pack
– Conformance Pack: Là một tập hợp các AWS Config Rules và các hành động khắc phục (remediation actions) được đóng gói sẵn, dùng để kiểm tra mức độ tuân thủ (compliance) của hệ thống AWS với các tiêu chuẩn, quy định hoặc chính sách bảo mật nội bộ.
– Vậy trường hợp này có thể bạn đã tạo 1 rule nào đó cho việc thực hành của bạn, VD như: ec2-ebs-encryption-by-default.
– Do đó để không bị tính phí, bạn vào AWS config , click Rules> tick vào chọn rule cần xóa > Click Actions > và xóa các rules đã tạo nhé như trong hình sau:

Chào em,
Câu hỏi của em rất hay, vậy tôi làm rõ để em nắm vững hơn nhé:
Trong bài lab, tôi đã sử dụng quyền cao nhất là user root để tạo 4 bucket, trong đó chỉ 2 bucket appconfig01 và appconfig02 được gán quyền qua policy S3RestrictedPolicy. Ở phần cấu hình policy, mặc dù có chọn “Any in this account” cho các resources khác như object, access point, hay objectlambdaaccess, nhưng:
Chỉ cấu hình 2 bucket appconfig được cấp quyền cho user truy cập rất rõ ràng trong phần Bucket ARN.
Các bucket khác như clientdata01, clientdata02 hoặc access point của các bucket này đều không được chỉ định trong policy, nên IAM users (như dev-user1, dev-user2) đều không thể truy cập được, trừ khi có chính sách bổ sung khác.
✅ Nói cách khác:
Cách cấu hình trong bài lab đã đảm bảo giới hạn quyền là 2 users (nếu dev-user2 được assume role) này chỉ được truy cập vào 2 bucket appconfig, mà không bị “thừa quyền” truy cập sang các tài nguyên khác.
Anh nghĩ có thể em chưa xem kỹ video bài lab, hoặc làm theo bài lab, xong tìm hiểu thật kỹ để hiểu chính sách đã áp dụng. Em vui lòng xem lại phần tạo policy và gán bucket ARN, và làm kỹ bài lab, sẽ thấy rõ cách quyền được giới hạn nhé.
Giải thích chi tiết:
dev-user1: Được gán trực tiếp policy S3RestrictedPolicy, cho phép thực hiện tất cả các hành động s3:* nhưng chỉ giới hạn trên hai bucket appconfig01 và appconfig02.
dev-user2: Được phép “assume” IAM Role có gán S3RestrictedPolicy, do đó cũng chỉ có quyền truy cập tương tự như dev-user1.
Các bucket khác (như clientdata01, clientdata02) và các tài nguyên khác không được chỉ định trong policy, nên cả hai users này không thể truy cập.
️ Lưu ý quan trọng:
Dù trong policy có chọn “Any in this account” cho các resource khác ngoài bucket, nhưng vì không có ARN cụ thể được chỉ định, nên các quyền này không có hiệu lực.
Để đảm bảo an toàn và tuân thủ nguyên tắc “least privilege” (ít đặc quyền nhất), chúng ta cần chỉ định rõ ràng ARN cho từng resource mà chúng ta muốn cấp quyền.
8. Hỏi: về tài khoản aws close và mở mới cho mình chỏi chút, mình có các tài khoảng aws mở sử dụng gần 1 năm thì close lại do đã sử dụng hết các dịch vụ free. trong thời gian sử dụng đó có phát sinh chi phí thì mình cũng thanh toán đúng hạn. các tài khoản đó đã đóng hơn 90 ngày, giờ mình tạo tài khoản aws mới, sử dụng lại địa chỉ mail cũ các tài khoản đã mở trước đó được không, khi tạo xong dùng lại địa chỉ mail cũ trước đó nó hiện ra màn hình yêu cầu mở lại tài khoản đã đóng. Nếu chọn mở lại tài khoản đã đóng, thì aws có ghi nhớ tài khoản cũ mình đã sử dụng hết các dịch vụ free trước đó không. hay vẫn được sử dụng các dịch vụ free 12 tháng như tạo mới?
Trả lời:
❓ Có thể sử dụng lại địa chỉ email cũ để tạo tài khoản AWS mới không?
Không được bạn nhé. Sau khi bạn đóng tài khoản AWS, địa chỉ email liên kết với tài khoản đó sẽ bị khóa và không thể sử dụng để tạo tài khoản mới. AWS khuyến nghị, nếu bạn muốn sử dụng lại địa chỉ email đó cho tài khoản mới, thì phải thay đổi địa chỉ email của tài khoản cũ trước khi đóng nó. Tài liệu AWS
Có thể mở lại tài khoản đã đóng sau 90 ngày không?
Không thể mở lại. Sau 90 ngày kể từ khi đóng, tài khoản AWS sẽ bị đóng vĩnh viễn và không thể khôi phục. Nếu bạn cứ đăng nhập bằng địa chỉ email cũ, AWS sẽ yêu cầu bạn mở lại tài khoản cũ, nhưng điều này chỉ khả thi trong vòng 90 ngày sau khi đóng tài khoản.
Có thể tạo tài khoản mới và nhận lại ưu đãi Free Tier 12 tháng không?
Có thể, nhưng với điều kiện:
Sử dụng địa chỉ email hoàn toàn mới chưa từng đăng ký AWS trước đó.
Không sử dụng lại địa chỉ email cũ đã liên kết với tài khoản AWS trước đây.
AWS xác định tính đủ điều kiện cho Free Tier dựa trên địa chỉ email. Việc sử dụng lại địa chỉ email cũ sẽ làm bạn không đủ điều kiện nhận ưu đãi Free Tier.
✅ Cách tạo tài khoản mới để nhận lại Free Tier:
Sử dụng địa chỉ email mới: Chọn một địa chỉ email chưa từng đăng ký AWS.
Đăng ký tài khoản AWS mới: Truy cập https://aws.amazon.com và tạo tài khoản mới với địa chỉ email mới.
Xác minh thông tin: Cung cấp thông tin thanh toán và xác minh tài khoản theo hướng dẫn của AWS.
Bắt đầu sử dụng Free Tier: Sau khi tài khoản được kích hoạt, bạn sẽ nhận được ưu đãi Free Tier 12 tháng.
⚠️ Lưu ý:
Không thể sử dụng lại địa chỉ email cũ đã liên kết với tài khoản AWS trước đây, ngay cả khi tài khoản đó đã bị đóng hơn 90 ngày.
9. Hỏi: về S3 cho mình hỏi chút, trong bài S3, mình thấy bạn nói S3 là dịch vụ Global( section 3, bài 19, phút thứ 4:50), nhưng sau tới các bài thực hành, mình thấy gõ chữ S3, có chọn theo region được vậy. Vậy S3 là dịch vụ Global hay dịch vụ theo region?
Trả lời:
Amazon S3 là dịch vụ lưu trữ các đối tượng trên đám mây do AWS cung cấp. Mặc dù S3 có thể truy cập từ bất kỳ ở đâu trên thế giới, nhưng dữ liệu được lưu trữ trong các “buckets” mà bạn tạo ra, và mỗi bucket này được gắn với một khu vực địa lý (region) cụ thể. Khi bạn tạo một bucket mới, bạn cần chọn region để xác định nơi dữ liệu sẽ được lưu trữ vật lý. Việc chọn region phù hợp giúp tối ưu hóa hiệu suất truy cập và tuân thủ các yêu cầu về quy định dữ liệu. Vì vậy, mặc dù S3 là một dịch vụ Global, nhưng dữ liệu và các bucket trong S3 được quản lý theo từng region cụ thể.
Bạn có thể tham khảo Link: https://aws.amazon.com/vi/s3/ và https://aws.amazon.com/vi/s3/faqs/
10. Hỏi: Cấu hình Truy cập EC2 theo rule. Nếu em muốn cấu hình chỉ cho phép Remote vào EC2 theo phạm vi địa lý, theo dải IP public riêng của công ty (Tức là chỉ cho phép những máy tính đang kết nối mạng công ty) mới có thể remote được tới EC2 thì có làm đc ko thầy? Còn lại các khu vực ngoài phạm vi sẽ không cho phép remote ấy ạ?
Trả lời:
Được, em có thể cấu hình để chỉ cho phép Remote (SSH, RDP) đến EC2 từ một dải IP public cụ thể, VD như dải IP của mạng công ty em, thông qua việc thiết lập các quy tắc inbound trong security groups. Như sau:
Security Groups:
Em có thể cấu hình một security group cho instance EC2 của mình với quy tắc inbound chỉ cho phép kết nối từ dải IP public của công ty (ví dụ: 203.0.113.0/28). Việc này có nghĩa là chỉ những máy tính trong dải IP đó mới có thể truy cập (remote) vào EC2.

Khu vực ngoài phạm vi:
Vì security group chỉ cho phép các IP public trong dải mà em chỉ định, nên tất cả các kết nối từ ngoài dải IP đó sẽ bị deny.
Đây là phương pháp thường được áp dụng để giới hạn truy cập từ các địa chỉ IP không mong muốn.
Lưu ý:
AWS không cung cấp trực tiếp chức năng “geo-block” (dựa trên vị trí địa lý) cho việc Remote vào EC2; Mà dựa trên whitelisting IP.
Nếu mạng công ty có IP động hoặc thay đổi, em sẽ cần có giải pháp theo dõi và cập nhật các IP này.
Nếu cần bảo mật mạnh hơn, em có thể kết hợp với các giải pháp VPN, để nhân viên từ công ty khi remote được cấp IP nội bộ hoặc IP đã được cố định.
Vậy, nếu em cấu hình đúng security group với dải IP public của mạng công ty, thì chỉ những máy tính từ mạng đó mới có thể remote đến EC2, còn các địa chỉ khác sẽ không được phép.
11. Hỏi: Khi tạo 1 EC2 thì thường sẽ có 2 loại IP (Public và Private) thì cả 2 địa chỉ này có set tĩnh cố định được không thầy? Ví dụ em muốn quản lý 1 con EC2 cố định theo địa chỉ IP để nó tương ứng với 1 rule nào đó về audit trên AWS?
Trả lời:
Về địa chỉ IP Private và IP Public, tôi trả lời em như sau nhé:
Địa chỉ IP Private: Khi tạo một instance EC2 trong VPC, địa chỉ IP private được gán cho network interface (ENI) của instance. Địa chỉ này thường được cấp khi instance được khởi tạo và sẽ không thay đổi trong suốt thời gian hoạt động của instance (trừ khi em thực hiện thay đổi cấu hình mạng thủ công). Như vậy, địa chỉ IP private có thể coi là tĩnh cố định đối với instance đó.
Địa chỉ IP Public: Nếu em bật tính năng “Auto-assign public IP” khi tạo instance, thì AWS sẽ gán một địa chỉ IP public cho instance. Tuy nhiên, địa chỉ IP public tự động này không phải là địa chỉ IP tĩnh cố định; nó có thể thay đổi nếu em dừng instance và sau đó khởi động lại (stop/start). Để có được địa chỉ IP public cố định, em cần tạo sau đó gán một Elastic IP cho instance. Elastic IP là một địa chỉ IP public tĩnh do AWS cung cấp và sẽ không thay đổi cho instance cho đến khi em xóa nó.

Tóm lại:
Địa chỉ IP Private: Có thể được coi là tĩnh cố định (cho đến khi em thay đổi cấu hình mạng của instance).
Địa chỉ IP Public: Mặc định là động (ephemeral) nếu được gán tự động; để có IP tĩnh, cần sử dụng Elastic IP.
Nếu em cần quản lý một instance theo địa chỉ IP cố định để áp dụng các quy tắc audit hoặc các yêu cầu khác, em có thể sử dụng:
Elastic IP cho địa chỉ public (nếu cần kết nối từ bên ngoài).
Và địa chỉ private sẽ tự động cố định coi như static IP cho instance khi được tạo ra.
12. Hỏi: User và AWS Account Khác Nhau Như Nào. Trong bài học này em thấy thầy tạo 2 kiểu tài khoản:
1 là AWS account: dev-user1, dev-user2
2 là User: user1, user2
Vậy 2 cái này mục đích chính có gì khác nhau và nên hiểu như nào trong môi trường Microsoft cho dễ hiểu thầy nhỉ?
Trả lời:
Hello em,
Tất cả các tài khoản mà tôi đã tạo trong bài học đều là IAM User. Tuy nhiên, mỗi loại tài khoản được cấp quyền truy cập vào các tài nguyên khác nhau. Em hãy xem kỹ các video bài giảng và tài liệu hướng dẫn trong phần tài nguyên để hiểu rõ hơn nhé.
Về sự khác biệt giữa AWS Account và IAM User, em có thể hình dung tương tự như trong môi trường Microsoft:
1. AWS Account
– Là một “container” riêng biệt chứa tất cả tài nguyên, cấu hình, và hóa đơn (billing) của em.
– Mỗi AWS Account có phạm vi bảo mật và quản lý riêng, giống như một subscription hoặc domain trong Active Directory.
– Ví dụ: nguyennh@gmail.com là một AWS Account, chứa các tài nguyên và chính sách riêng.
2. User (IAM User)
– Là danh tính IAM được tạo trong một AWS Account để cấp quyền truy cập vào các tài nguyên cụ thể.
– Trong môi trường Microsoft, IAM User tương tự như một user account được tạo trong một domain.
– Ví dụ: user1 và user2 là các IAM User trong một AWS Account, được phân quyền để thực hiện các tác vụ cụ thể.
Tóm lại:
AWS Account giống như một domain hoặc subscription trong Microsoft, nơi quản lý toàn bộ tài nguyên và thanh toán.
IAM User giống như một user account trong domain, chỉ có quyền truy cập vào tài nguyên trong tài khoản AWS mà nó thuộc về.
13. Hỏi: Em cảm ơn thầy đã phản hồi, em có thể summary lại theo cách em hiểu như sau, thầy correct xem đúng ko nhé.
1. AWS Account: Nó giống như khi em mua 1 số lượng licenses của Microsoft, em đã được cấp 1 tài khoản gọi là quản trị toàn bộ tài nguyên của MS licenses để tạo các dịch vụ như EntraID, Intune, Exchange, Quản lý Subscription, Bill
2. IAM User: Chính là các Users được tạo ra trên EntraID (Azure AD), các IAM này cũng có những tài khoản set quyền Administrator để quản lý toàn bộ các IAM Users
Thầy correct giúp xem em hiểu đúng ko nhé?
Trả lời:
Em hiểu theo cách liên tưởng với Microsoft là khá tốt, nhưng có một số điểm chưa hoàn toàn chính xác. Vậy tôi giải thích lại để giúp em hiểu đúng hơn nhé:
1. AWS Account
– AWS Account giống như một tài khoản gốc (root account) để quản lý toàn bộ tài nguyên và dịch vụ AWS.
– Nó tương tự như khi em mua một Microsoft Tenant ( Microsoft 365 Org) để quản lý các dịch vụ như Entra ID (trước đây là Azure AD), Intune, Exchange, nhưng AWS Account không phải là một tập hợp các license vì đây là chúng ta đăng ký một AWS Account chứ không phải là mua bản quyền phần mềm .
-Một AWS Account có thể chứa nhiều dự án, dịch vụ và tài nguyên khác nhau, không hoàn toàn tương đương với cách Microsoft Subscription hoạt động. Trong AWS, chúng ta không có “gói dịch vụ” cố định mà chỉ sử dụng tài nguyên theo nhu cầu và trả tiền theo mức sử dụng (pay-as-you-go). Em có thể quản lý Billing (Hóa Đơn Thanh toán), chính sách bảo mật, và tạo nhiều người dùng IAM để quản trị họ và cho phép họ sử dụng các tài nguyên AWS.
2. IAM User
– IAM User trong AWS không hoàn toàn giống với Entra ID Users (Azure AD Users).
– IAM User là một tài khoản người dùng được tạo trong dịch vụ AWS IAM để cấp quyền truy cập cho IAM User vào các dịch vụ AWS.
– Khác với Entra ID Users (Azure AD Users), IAM User không phải là một directory tập trung như Azure AD để Azure AD User có mục đích là có thể đăng nhập vào nhiều ứng dụng SaaS hoặc dịch vụ Microsoft như Microsoft 365, Exchange, Intune, SharePoint, Teams, cũng như các ứng dụng SaaS bên ngoài (nếu được cấp quyền).
– IAM User chỉ có thể truy cập các tài nguyên trong chính AWS Account mà nó được tạo ra, và chỉ khi nào chúng ta sử dụng IAM Policies cấp quyền cho IAM User thì IAM User mới có thể truy cập vào 1 số tài nguyên được chỉ định trong chính AWS Account này.
– IAM User có thể có quyền quản trị (Administrator), nhưng tài khoản IAM mạnh nhất không phải IAM User, mà là Root User của AWS Account.
Tóm lại, em hiểu theo hướng Microsoft là khá tốt, nhưng cần điều chỉnh lại một số điểm:
+ AWS Account khác với Microsoft Licenses, nhưng gần giống với Microsoft Tenant.
+ IAM Users có 1 số điểm khác với Azure AD Users, Azure AD User có thể đăng nhập vào nhiều ứng dụng SaaS, nhưng IAM User KHÔNG có khả năng này.
14. Hỏi: Anh Phương ơi Em hỏi 1 chút. Em muốn đi theo và học thêm nữa về mảng Cloud. Cụ thể Em muốn học về Cái bảo mật đám mây (Cloud Native Application Protection Platform – CNAPP) Nội dung học cụ thể cho món này thì Em cũng tìm hiểu trên mạng, tuy nhiên chính xác và tỷ mỉ thì nhờ Anh Phương advice thêm giúp Em chỗ này với Anh nhé?
Trả lời:
CNAPP (Cloud Native Application Protection Platform), thường yêu cầu các kỹ năng và kiến thức sau em nhé:
– Kiến thức nền tảng về Cloud Computing:
Thành thạo ít nhất một trong các nền tảng đám mây chính như AWS, Azure hoặc Google Cloud.
Hiểu biết về kiến trúc cloud, mô hình dịch vụ (IaaS, PaaS, SaaS) và cách thiết lập các dịch vụ này một cách an toàn.
– Công nghệ container và Kubernetes:
Làm việc với Docker và các công nghệ container khác.
Quản lý và bảo mật các cluster Kubernetes là một điểm mạnh được nhiều nhà tuyển dụng đánh giá cao.
– DevSecOps và CI/CD:
Kiến thức về tích hợp bảo mật vào quy trình phát triển phần mềm (DevOps), bao gồm việc tự động hóa kiểm tra bảo mật và triển khai (CI/CD pipeline).
Sử dụng các công cụ quét lỗ hổng và kiểm tra bảo mật tự động.
Hiểu biết về bảo mật ứng dụng và bảo mật hạ tầng:
Nắm vững các khái niệm về kiểm soát truy cập, mã hóa, giám sát và phát hiện xâm nhập.
Kiến thức về các tiêu chuẩn, framework và best practices bảo mật.
– Kỹ năng về tự động hoá và scripting:
Biết sử dụng các ngôn ngữ scripting như Python, Bash… để tự động hóa quy trình bảo mật.
– Các chứng chỉ chuyên môn:
Các chứng chỉ liên quan đến bảo mật (như CISSP, CCSP) và các chứng chỉ của nền tảng đám mây (ví dụ AWS Certified Security Specialty) sẽ tạo lợi thế lớn.
– Kiến thức chuyên sâu về CNAPP:
Hiểu các thành phần cấu thành của CNAPP như quản lý cấu hình bảo mật, quét lỗ hổng, bảo vệ runtime và giám sát hoạt động.
Thông thường, CNAPP tích hợp các giải pháp bảo mật cho các workload trên cloud native, từ việc xây dựng (build time) đến triển khai (runtime).
15. Hỏi: Ý tưởng của em là xây dựng một hệ thống bảo mật cho mạng AWS bằng cách:
(1)Triển khai các máy chủ EC2 (loại t3.medium) trong vùng mạng public DMZ, đóng vai trò như một tường lửa kết hợp hệ thống phát hiện và ngăn chặn xâm nhập (IDPS).
(2) Sử dụng Auto Scaling để đảm bảo hệ thống có thể mở rộng tự động khi lưu lượng tăng.
(3) Các máy chủ này sẽ phân tích lưu lượng đến từ Internet và phát hiện các hành vi bất thường dựa trên mô hình đã được huấn luyện trước bằng Amazon SageMaker.
(4) Dữ liệu về lưu lượng mạng (logs) sẽ được lưu vào VPC Flow Logs, sau đó chuyển vào bộ lưu trữ S3.
(5) Các logs này sẽ được gán nhãn (bình thường/bất thường) và sử dụng để huấn luyện lại mô hình, giúp cải thiện khả năng phát hiện của hệ thống IDPS trên các máy chủ EC2 ở vùng public.”
Dạ anh có thể cho em lời khuyên mô hình VPC và Security Group trên AWS mà em đã tạo từ mô hình mạng doanh nghiệp như vậy đã hợp lý chưa ạ? Em vận dụng được kiến thức về EC2, S3, VPC ở trong mô hình này ạ?