
Chúng ta cần biết là việc backup dữ liệu cho Servers là cực kỳ quan trọng cho cá nhân và doanh nghiệp, nhưng chỉ backup dữ liệu trong hệ thống nội bộ là chưa đủ. Vì có thể xảy ra các thảm họa xảy ra như cháy nổ, hay động đất-thiên tai, hoặc nghiêm trọng hơn: Hệ thống bị ransomware mã hóa toàn bộ dữ liệu — kể cả hệ thống backup nội bộ, điều này đã xảy ra với không ít các công ty trong thời gian gần đây. Ngoài ra, nhiều doanh nghiệp còn phải đáp ứng các tiêu chuẩn ISO / quy trình an toàn thông tin, trong đó off-site backup là yêu cầu bắt buộc. Vì vậy, việc backup dữ liệu lên đám mây là một bước rất quan trọng.
Chia sẻ với các bạn một kinh nghiệm thực tế của mình, mình từng làm việc tại một công ty nơi toàn bộ hệ thống servers bị hỏng do sét lan truyền. Sự cố này không chỉ làm hỏng các máy chủ mà còn phá hủy toàn bộ ổ cứng, làm cho dữ liệu không thể phục hồi. Qua kinh nghiệm thực tế này cho thấy rõ rằng rủi ro vật lý là thứ không thể kiểm soát hoàn toàn, và việc backup dữ liệu cần được tách biệt hoàn toàn khỏi hệ thống on-prem.
Chính vì vậy trong bài viết này, tôi sẽ hướng dẫn bạn cách Backup máy chủ on-premise lên đám mây Amazon S3 một cách đơn giản, an toàn và chuẩn production, để bạn có thể áp dụng ngay vào hệ thống của mình. Hiện nay, giá lưu trữ dữ liệu trên Amazon S3 rất thấp, điều này cho thấy Amazon S3 không chỉ là giải pháp backup an toàn mà còn rất tiết kiệm chi phí lưu trữ dữ liệu cho doanh nghiệp.
Hướng dẫn này phù hợp cho System Admin, kỹ sư DevOps hay các doanh nghiệp đang cần tìm kiếm một phương án backup dữ liệu tin cậy. Vậy chúng ta hãy bắt đầu nhé!
Contents
- 1 Tại sao nên sao lưu dữ liệu lên đám mây AWS?
- 2 Bước 1: Tạo Bucket trên Amazon S3
- 3 Bước 2: Tạo user IAM chuyên dụng cho backup
- 4 Bước 3: Tạo Access Key cho IAM User
- 5 Bước 4: Cài đặt AWS CLI trên máy chủ cần BACKUP data
- 6 Bước 5: Cấu hình thông tin đăng nhập AWS CLI
- 7 Bước 6: Sao lưu dữ liệu lên S3
- 8 📌 aws s3 sync là gì?
- 9 Bước 7: Thử khôi phục dữ liệu từ S3
- 10 Bước 8: Tự động hóa sao lưu với Cron
- 11 Kết luận
Tại sao nên sao lưu dữ liệu lên đám mây AWS?
Backup dữ liệu là yếu tố sống còn của doanh nghiệp. Nếu tất cả bản Backups ở một nơi, rủi ro mất sạch dữ liệu sẽ rất cao khi gặp sự cố hư hỏng phần cứng ví dụ như phòng Server gặp phải sét đánh, hay sự cố cháy nổ làm hỏng tất cả các phần cứng của các thiết bị trong phòng, hoặc ransomware. Đối với các công ty, giải pháp backup lên AWS S3 mang lại nhiều lợi ích:
-
An toàn, bền vững: Amazon S3 cam kết độ bền vững cho dữ liệu lên đến 99.999999999% (11 9’s) bằng cách lưu trữ dữ liệu trên nhiều regions (AZ). Nhờ đó, dữ liệu của bạn luôn có dự phòng.
-
Tiết kiệm chi phí: S3 có chi phí lưu trữ rất thấp và cung cấp nhiều lớp lưu trữ (Standard, Infrequent Access, Glacier) giúp tối ưu chi phí theo nhu cầu.
Với những lý do trên, việc backup dữ liệu lên AWS S3 là lựa chọn được khuyến khích, nhất là khi bảo mật dữ liệu là ưu tiên hàng đầu.
Bước 1: Tạo Bucket trên Amazon S3
Trước tiên, bạn cần đăng nhập vào AWS Console của bạn ( việc tạo 1 tài khoản AWS rất dễ, bạn có thể google tìm kiếm hướng dẫn tạo tài khoản AWS và làm theo) vào dịch vụ S3 và click Create bucket.
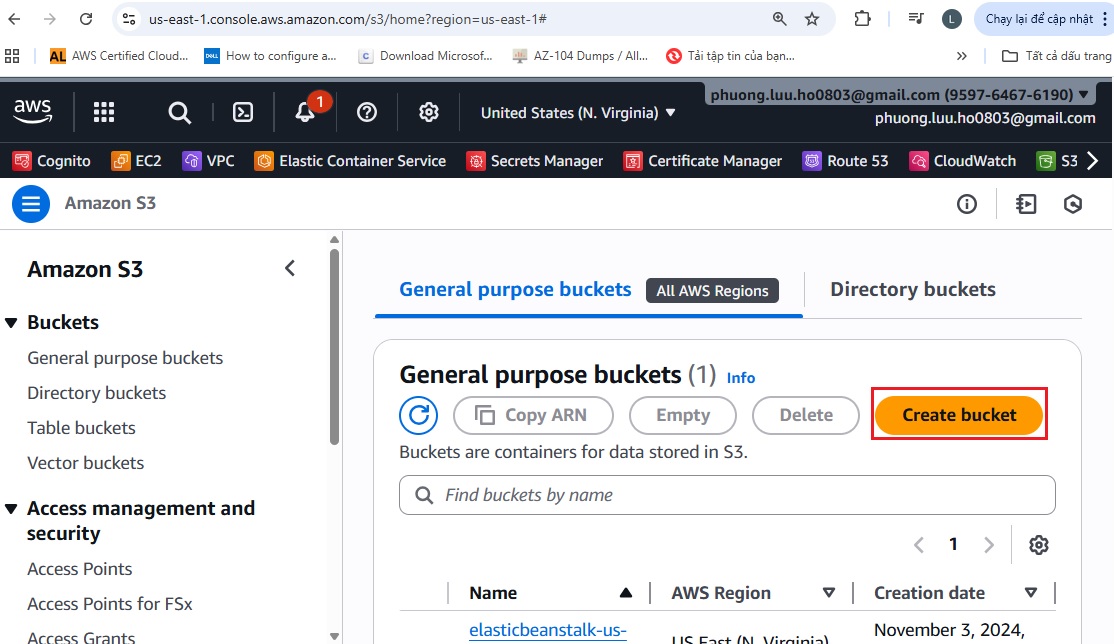
-
Đặt tên cho bucket: Ví dụ đặt tên cho bucket là
phuong-linux-backup-prod(tên phải duy nhất, chỉ gồm chữ thường và số).
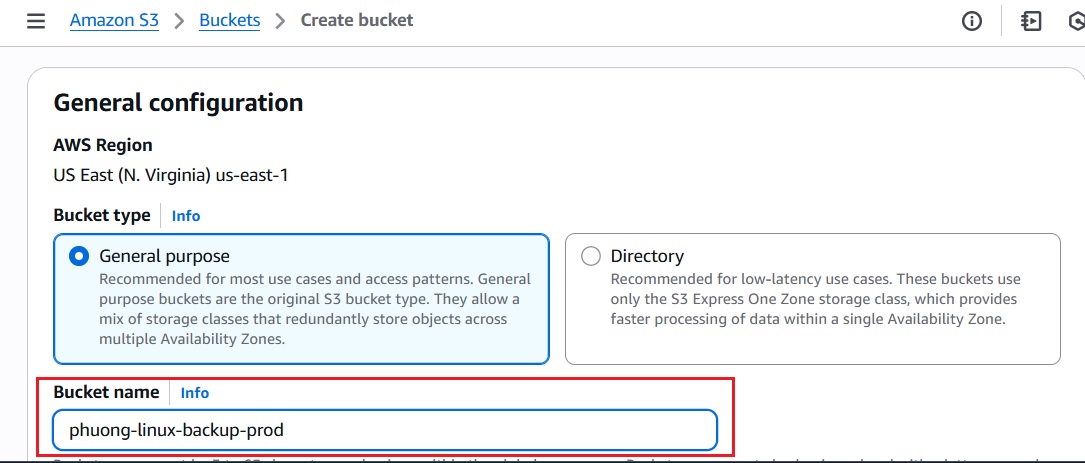
-
Bật tính năng Versioning: Tình năng này giúp lưu nhiều phiên bản files, tránh mất dữ liệu khi bị ghi đè hoặc bị mã hóa data.

Cuối cùng, click Create bucket. Lúc này, bạn đã có một S3 bucket sẵn sàng để cho việc backup dữ liệu của bạn.
Bước 2: Tạo user IAM chuyên dụng cho backup
Để đảm bảo an toàn cũng như dễ dàng trong quản lý, chúng ta nên tạo user IAM riêng cho việc backup dữ liệu.
-
Trong AWS Console, vào IAM > Users > Create user.
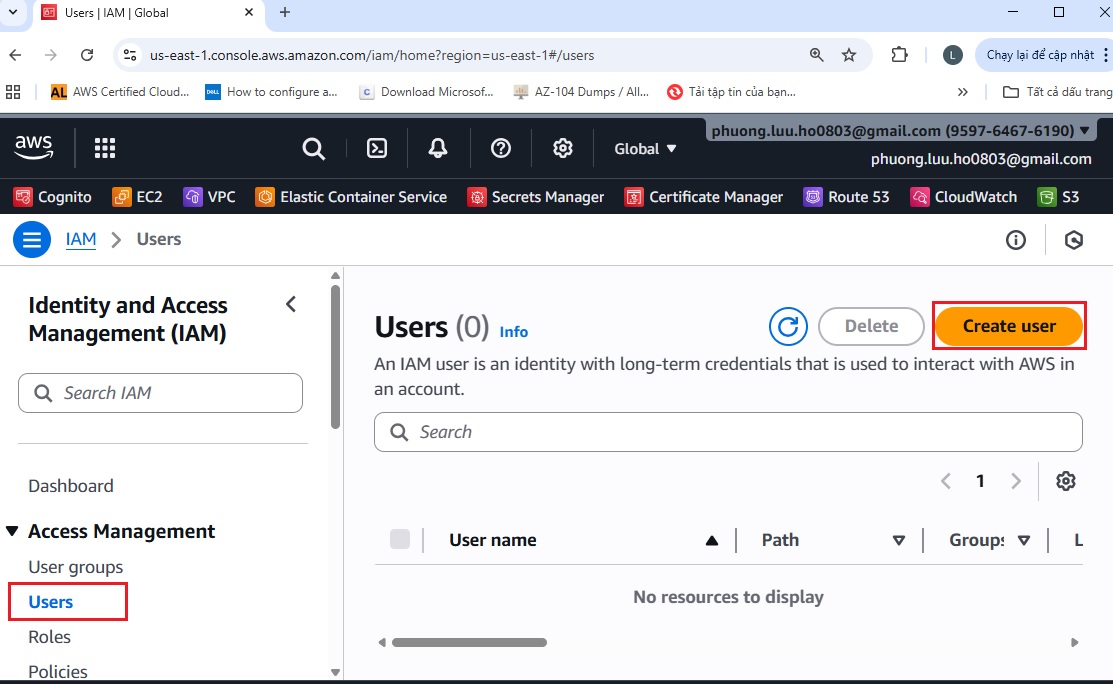 b
b
-
Đặt tên cho IAM user (ví dụ
backup_user).

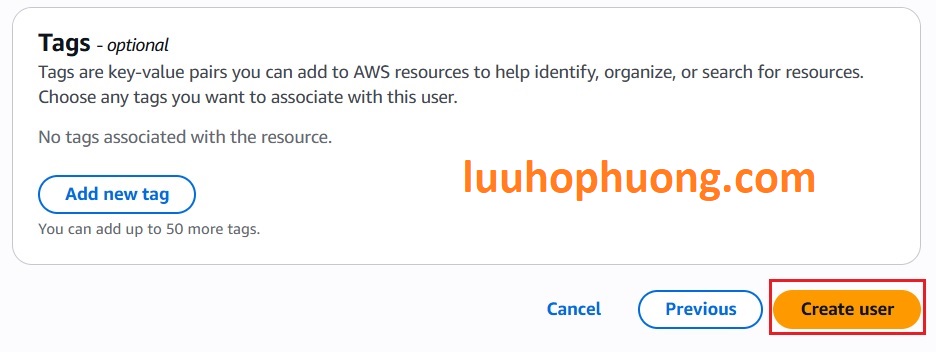
-
Chúng ta cần quyền đọc ghi bucket này cho IAM User, thay vì gán các policies có sẵn, chúng ta sẽ tạo inline policy để giới hạn quyền cho IAM user này.
Sau khi IAM user được tạo, click vào IAM user đó:
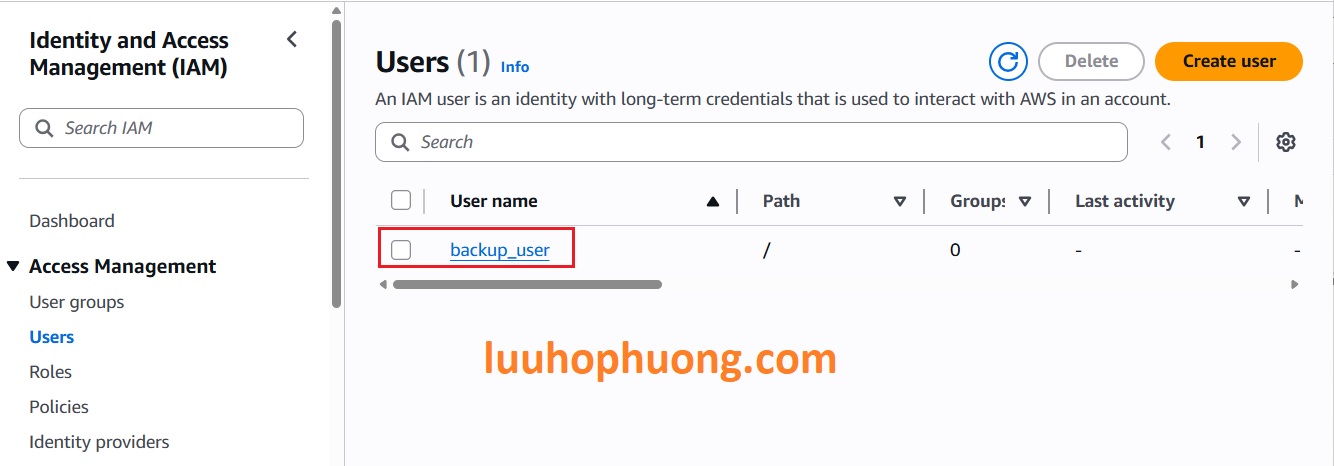
vào Permissions > Add permissions > Click Create inline policy.
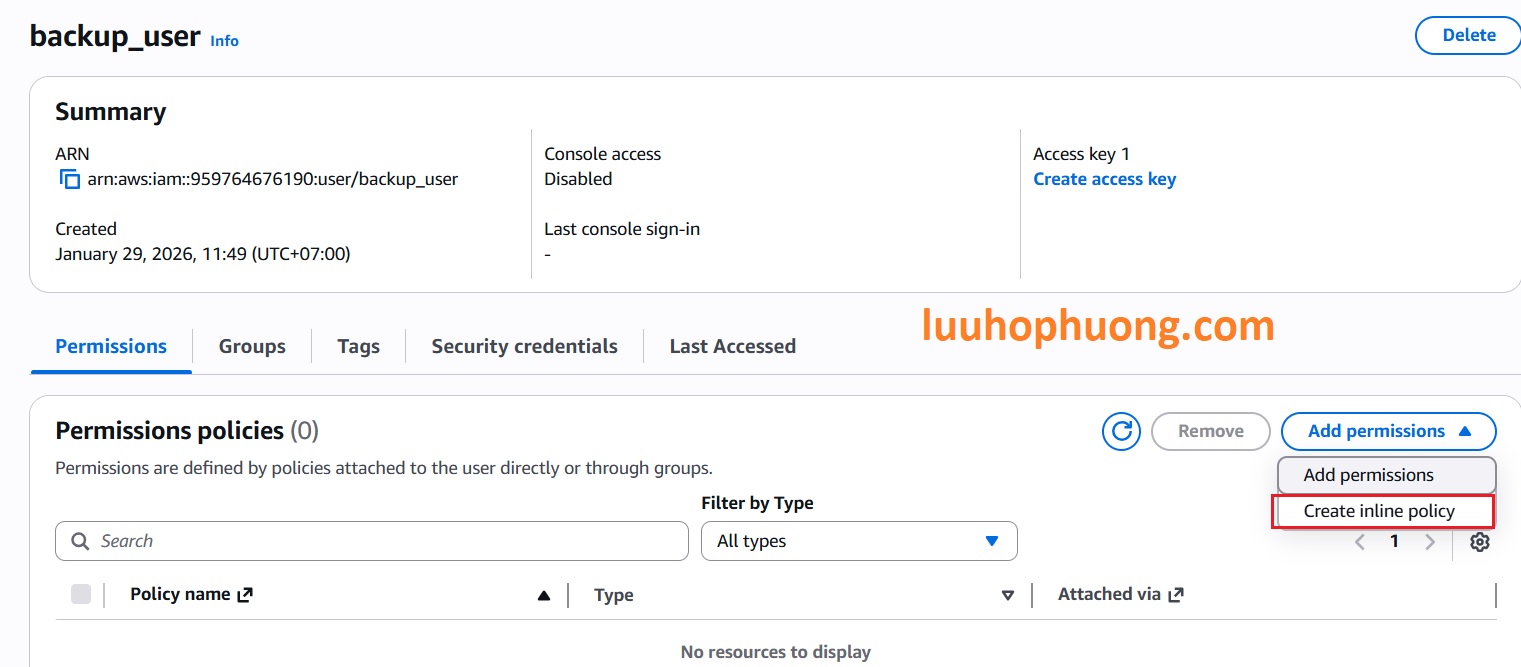
Dán đoạn JSON sau vào và Click vào Next:
Lưu ý bạn cần phải thayYOUR-linux-backup-prod thành tên bucket của bạn. Sau đó, click Next để tiếp tục việc tạo chính sách.
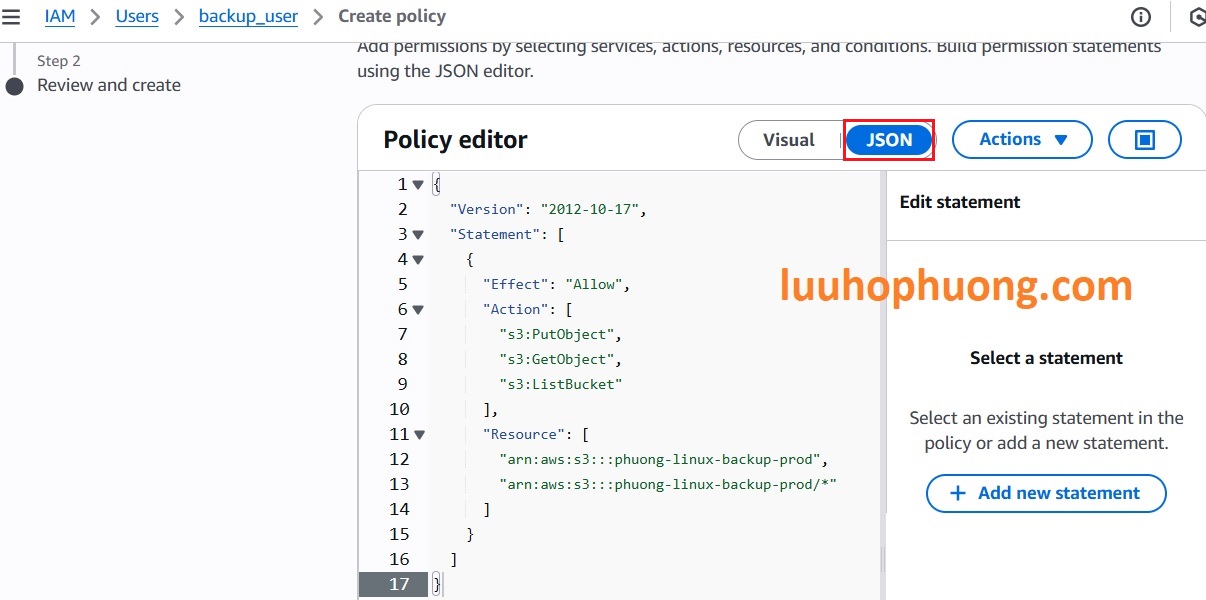
Tiếp theo đặt tên cho Policy ví dụ như s3_backup_policy và Click Create Policy để tạo Policy. Và bây giờ IAM User này chỉ có quyền ghi, đọc và liệt kê trong phạm vi bucket YOUR-linux-backup-prod, IAM User này không thể truy cập vào tài nguyên AWS khác. Quy trình này đảm bảo quyền truy cập được giới hạn một cách chặt chẽ và bảo mật.
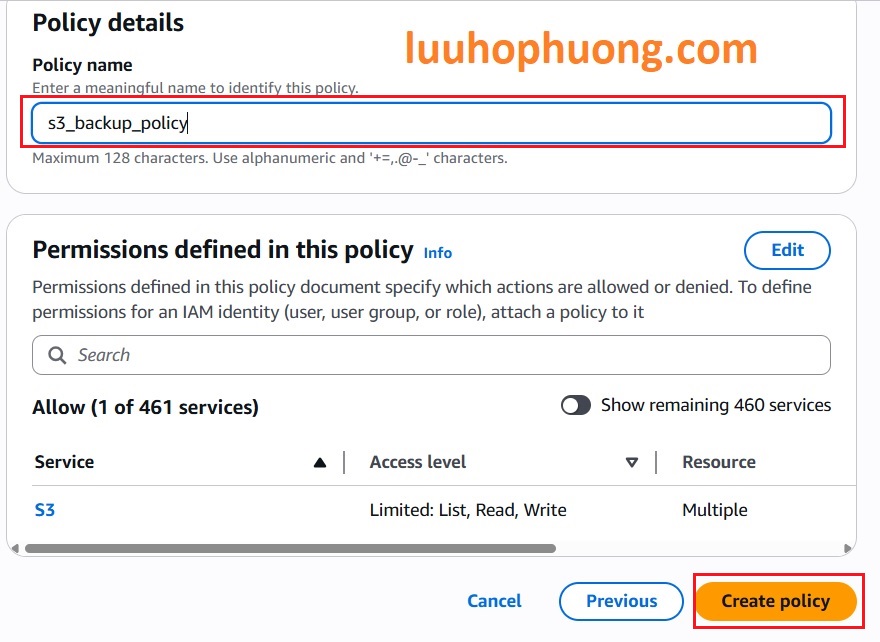
Bước 3: Tạo Access Key cho IAM User
Tiếp theo, cần tạo Access Key cho user backup_user mới. Vẫn trong IAM, click user đó và vào tab Security credentials:
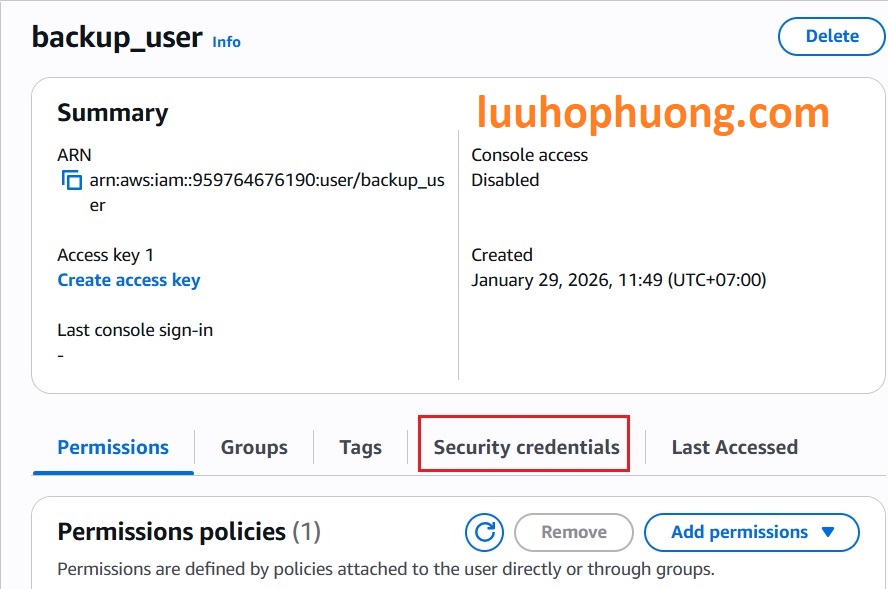
Click Create access key:
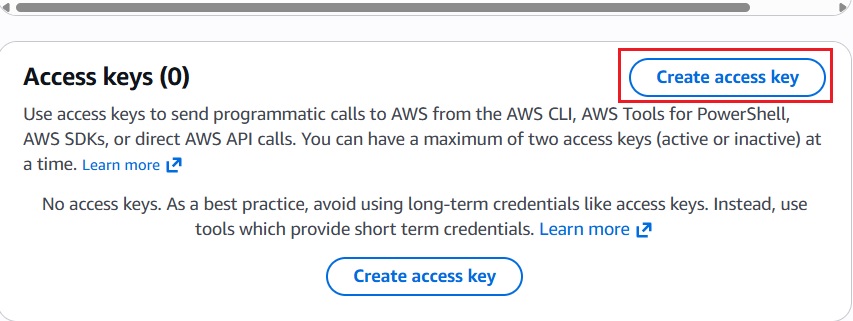
Chọn loại CLI (Command Line Interface) > Click Next > và click Create access key.

AWS sẽ hiện Access Key ID và Secret Access Key. Bạn hãy copy cẩn thận hai thông tin này ( Key này chỉ hiển thị một lần duy nhất ):

Bước 4: Cài đặt AWS CLI trên máy chủ cần BACKUP data
Trên máy chủ Linux cần phải Backup dữ liệu trong hệ thống, cài đặt AWS CLI để có thể làm việc với AWS S3 từ môi trường dòng lệnh. Ví dụ với Ubuntu:
Đầu tiên cần update hệ thống Linux Ubuntu:
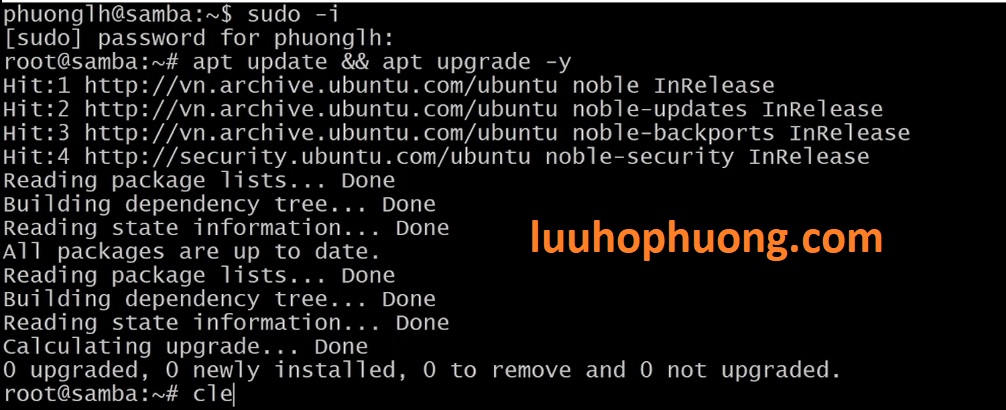
sudo apt install -y curl unzip
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip
sudo ./aws/installSau khi cài đặt xong AWS CLI, hãy kiểm tra phiên bản:
Kết quả sẽ hiển thị phiên bản AWS CLI đã được setup, sau đó xác nhận quá trình cài đặt thành công.

Bước 5: Cấu hình thông tin đăng nhập AWS CLI
Bây giờ chúng ta sẽ cấu hình AWS CLI với Access Key vừa tạo. Vậy hãy chạy lệnh sau:
Nhập lần lượt các thông tin sau:
-
AWS Access Key ID: (Key ID đã lưu)
-
AWS Secret Access Key: (Secret Access Key đã lưu)
-
Default region name: ví dụ
ap-southeast-1(Singapore) hoặc Region mà bạn đã tạo S3 Bucket của bạn. -
Default output format:
json(hoặctext).
AWS CLI sẽ lưu thông tin này vào file ~/.aws/credentials và ~/.aws/config.
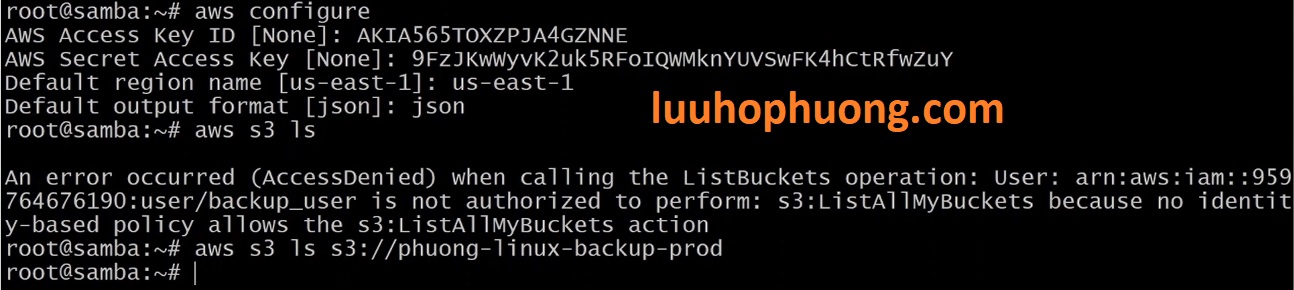
Tiếp theo chúng ta kiểm tra xem cấu hình đã đúng và có thể hoạt động không: Ví dụ, liệt kê bucket backup:
Lệnh trên sẽ hiển thị nội dung trong bucket nếu cấu hình đúng. Nếu có AccessDenied ở lệnh liệt kê chung tất cả các AWS Buckets là lệnh: aws s3 ls, đó là vì IAM user này chỉ được giới hạn quyền trên backup bucket . Quan trọng là lệnh trên thành công khi gõ đúng đường dẫn đến Buckup bucket, điều đó chứng tỏ quyền hạn đã được cấu hình giới hạn một các chính xác.
Bước 6: Sao lưu dữ liệu lên S3
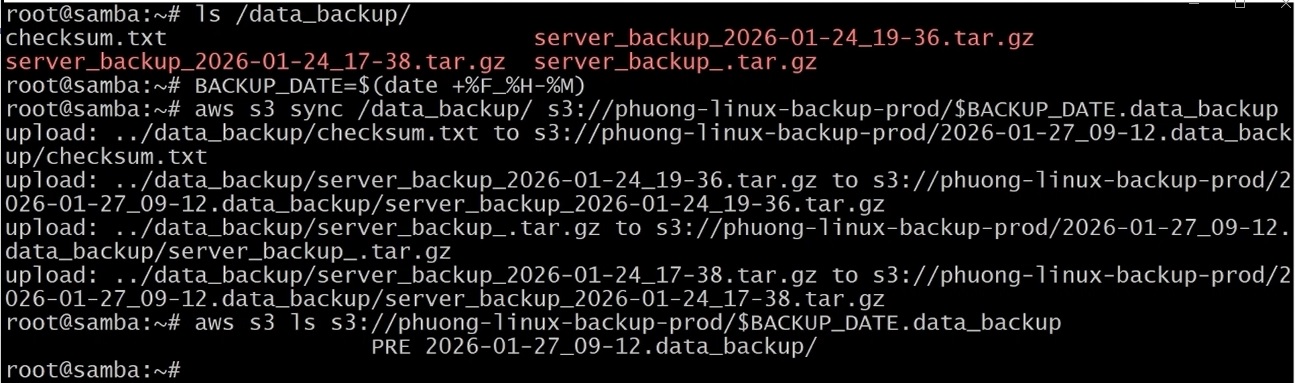
Giả sử bạn có thư mục dữ liệu cần sao lưu, ví dụ /data_backup. Đầu tiên, tạo biến BACKUP_DATE để đánh dấu bản BACKUP theo ngày tháng năm:
Sau đó, dùng lệnh aws s3 sync để đồng bộ dữ liệu lên S3:
Lệnh này sẽ tạo thư mục chứa ngày giờ trên S3 và đẩy toàn bộ nội dung.
📌 aws s3 sync là gì?
Lệnh aws s3 sync là một công cụ dòng lệnh của AWS CLI dùng để “synchronize” — tức là đồng bộ hóa nội dung giữa hai thư mục nguồn và đích:
-
Một thư mục local trên máy/ server
-
Và một bucket hoặc prefix trên Amazon S3
Khi chạy, lệnh này sẽ:
✔️ Tự động so sánh các file
✔️ Chỉ upload (hoặc download) những files MỚI hoặc ĐÃ THAY ĐỔI
✔️ Giữ lại cấu trúc thư mục đích giống như thư mục nguồn
✔️ Duyệt đệ quy cả thư mục con
✔️ Không upload lại những files chưa thay đổi ❗
👉 Đây là điều quan trọng nhất để dùng cho việc backup:
Như vậy lệnh này hoạt động như một “incremental sync” ở mức file-level, giúp tiết kiệm băng thông và thời gian.
Sau khi chạy xong lệnh, chúng ta cần kiểm tra để xác nhận baclup dữ liệu có thành công hay không:
Kết quả sẽ liệt kê các files đã được sao lưu thành công. Từ bước này, dữ liệu của bạn đã được lưu an toàn trên S3, tách biệt hoàn toàn khỏi máy chủ nội bộ.
Bước 7: Thử khôi phục dữ liệu từ S3
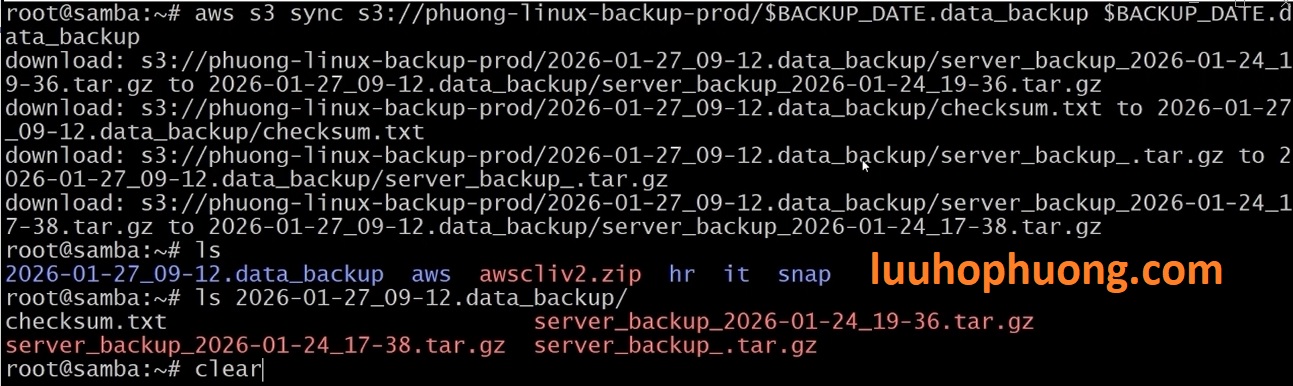
Giả sử thư mục /data_backup trên máy chủ bị xóa hoặc chuyển đi. Chạy lệnh sau để khôi phục dữ liệu về thư mục mới:
Sau đó, chạy:
Các files trong /restore_test sẽ giống hệt bản backup ban đầu, qua đó xác nhận quá trình khôi phục dữ liệu đã thành công.
Bước 8: Tự động hóa sao lưu với Cron
Để backup dữ liệu chạy một cách tự động vào mỗi đêm hàng ngày, chúng ta cần mở crontab:
Thêm vào dòng lệnh sau ( BACKUP sẽ chạy vào lúc 2h sáng hàng ngày):
Thay /usr/local/bin/aws bằng đường dẫn phù hợp nếu cần. Từ bây giờ, hệ thống sẽ tự động backup dữ liệu vào S3 mỗi ngày, đảm bảo dữ liệu luôn an toàn.
Kết luận
Qua bài viết này, bạn đã biết cách:
-
Tạo bucket S3 với tính năng versioning để lưu trữ bản backup an toàn.
-
Tạo IAM user giới hạn quyền, chỉ có quyền hạn cần thiết trên bucket.
-
Cài đặt và cấu hình AWS CLI để backup dữ liệu một cách tự động.
-
Thử nghiệm khôi phục dữ liệu từ S3.
-
Tự động hóa quá trình backup dữ liệu bằng cron để chạy backup hàng ngày.
Đây là quy trình chuẩn, có thể áp dụng ngay trong môi trường thực tế của bạn. Việc BACKUP dữ liệu lên AWS S3 không chỉ tăng cường mức độ an toàn dữ liệu mà còn giúp tiết kiệm chi phí lưu trữ cho công ty của bạn.
#AWS #S3 #Backup #DevOps #Linux #Cron #BảoMật


