Trong vai trò sysadmin hoặc kỹ sư DevOps, bạn không thể nhắm mắt làm ngơ trước tình trạng hệ thống có vấn đề về hiệu xuất. Đừng để đến khi server sập vì quá tải hay dữ liệu rác đầy ổ đĩa mới tá hỏa đi tìm nguyên nhân. Bài viết này hướng dẫn từng bước cách triển khai hệ thống monitoring và logging để hướng dẫn bạn Monitor hiệu xuất và các tài nguyên hệ thống trong Linux (tương tự cho CentOS 9 hoặc CentOS Stream) một cách thực tế nhất và không màu mè. Chúng ta sẽ sử dụng các công cụ có sẵn của Linux – những “DevOps tools for Linux” kinh điển – để giám sát hiệu năng, quản lý log hệ thống và thiết lập cảnh báo. Nội dung bao gồm:
-
Giám sát hiệu xuất và tài nguyên hệ thống: Dùng
top,htop,df,du,vmstatđể theo dõi CPU, RAM, dung lượng ổ đĩa và phát hiện bottleneck. -
Thiết lập logging và auditing: Bật và cấu hình dịch vụ ghi log (
rsyslog), xem log vớijournalctl, tạo báo cáo log tự động bằnglogwatch. -
Triển khai công cụ giám sát hệ thống (Cockpit): Cài đặt và sử dụng Cockpit (Web Console) trên RHEL để quan sát hệ thống real-time qua giao diện web, xem log real-time và thiết lập cảnh báo cơ bản.
-
Thử thách cuối: Mô phỏng một kịch bản quá tải hệ thống bằng script, sau đó vận dụng các công cụ trên để kiểm tra dấu hiệu CPU quá tải, disk full, lỗi dịch vụ (ví dụ SSH), và quan sát cảnh báo trên Cockpit.
Không dài dòng nữa, chúng ta bắt tay vào việc monitoring RHEL 9 ngay bây giờ. Lưu ý: Các lệnh dưới đây nên chạy với quyền sudo hoặc người dùng có quyền admin.
Contents
Giám sát hiệu năng và tài nguyên hệ thống
Đầu tiên, hãy làm quen với những công cụ dòng lệnh cổ điển nhưng hiệu quả để theo dõi hiệu suất hệ thống Linux. Đây là những công cụ phải biết cho bất kỳ ai làm việc với CentOS server monitoring hay RHEL:
-
top– Xem tiến trình đang chạy, mức sử dụng CPU, RAM, load average… theo thời gian thực. -
htop– Phiên bản nâng cấp của top, giao diện thân thiện hơn, cho phép điều hướng và lọc tiến trình dễ dàng. -
df– Kiểm tra dung lượng đĩa còn trống trên các phân vùng. -
du– Kiểm tra dung lượng thư mục hoặc files, giúp tìm ra thư mục nào “ngốn” nhiều dung lượng. -
vmstat– Thống kê tổng quan về CPU, bộ nhớ, I/O… để phát hiện nút nghẽn cổ chai (bottleneck) hệ thống.
Chúng ta sẽ lần lượt sử dụng các công cụ trên để giám sát tài nguyên.
Theo dõi tiến trình và CPU với top
Lệnh top hiển thị danh sách các tiến trình đang chạy, sắp xếp mặc định theo %CPU. Bạn sẽ thấy các cột thông tin như thời gian hệ thống chạy (uptime), tải trung bình (load average), %CPU, %RAM mỗi tiến trình, v.v. Đây là Task Manager của Linux. Nếu server của bạn lag hoặc quạt CPU kêu như máy xay sinh tố, top là nơi đầu tiên cần mở để chúng ta xem có vấn đề gì đang xảy ra đối với hệ thống Linux của chúng ta.
Chúng ta thử tạo một tiến trình giả liên tục tiêu tốn CPU/IO để thấy rõ tác dụng của top. Chạy lệnh sau để tạo một process chạy nền ghi không ngừng vào file file.txt (hãy chuẩn bị dừng nó kẻo đầy ổ đĩa!):
Lệnh trên sẽ ghi chuỗi "Validating top works" vào file mỗi giây vô tận. Dấu & cho phép chạy nền, trả về prompt ngay. Sau khi chạy, terminal sẽ in ra một PID (Process ID) cho tiến trình nền này (ngay sau ký hiệu [1] trong output). Ghi nhớ PID đó – lát nữa chúng ta sẽ dùng nó.
Bây giờ, chạy top để xem tiến trình vừa tạo:
Khi top đang chạy, bạn sẽ thấy tiến trình bash hoặc echo "Validating top works" (tùy cách hiển thị) chiếm CPU. Để dừng tiến trình đó trực tiếp từ top, làm như sau:
-
Nhấn phím K trong giao diện
top. Ngay lập tứctopsẽ yêu cầu nhập PID của tiến trình cần kill. -
Nhập PID bạn đã ghi nhớ ở bước trên, rồi nhấn Enter.
-
topsẽ hỏi bạn chọn tín hiệu (signal) để gửi. Mặc định là15(SIGTERM – báo tiến trình tự kết thúc). Ở đây ta muốn “xử đẹp” ngay, hãy nhập9(SIGKILL) rồi Enter. -
Tiến trình sẽ bị kill. Nhấn Q để thoát
top.
Nếu mọi thứ suôn sẻ, tiến trình “while true” kia đã bị diệt và không còn ghi vào file nữa. Chúc mừng, bạn vừa sử dụng top để theo dõi và quản lý tiến trình như một IT pro.
Mẹo: Trong
top, phím H sẽ hiện hướng dẫn (nếu bạn quên phím tắt). Ngoài ra, có thể nhấn SHIFT + M để sắp xếp theo RAM, SHIFT + P để sắp xếp theo CPU, 1 để hiển thị tải trên từng CPU core, v.v. Biết mấy phím này giúp bạn đỡ lóng ngóng khi cần phân tích nhanh.
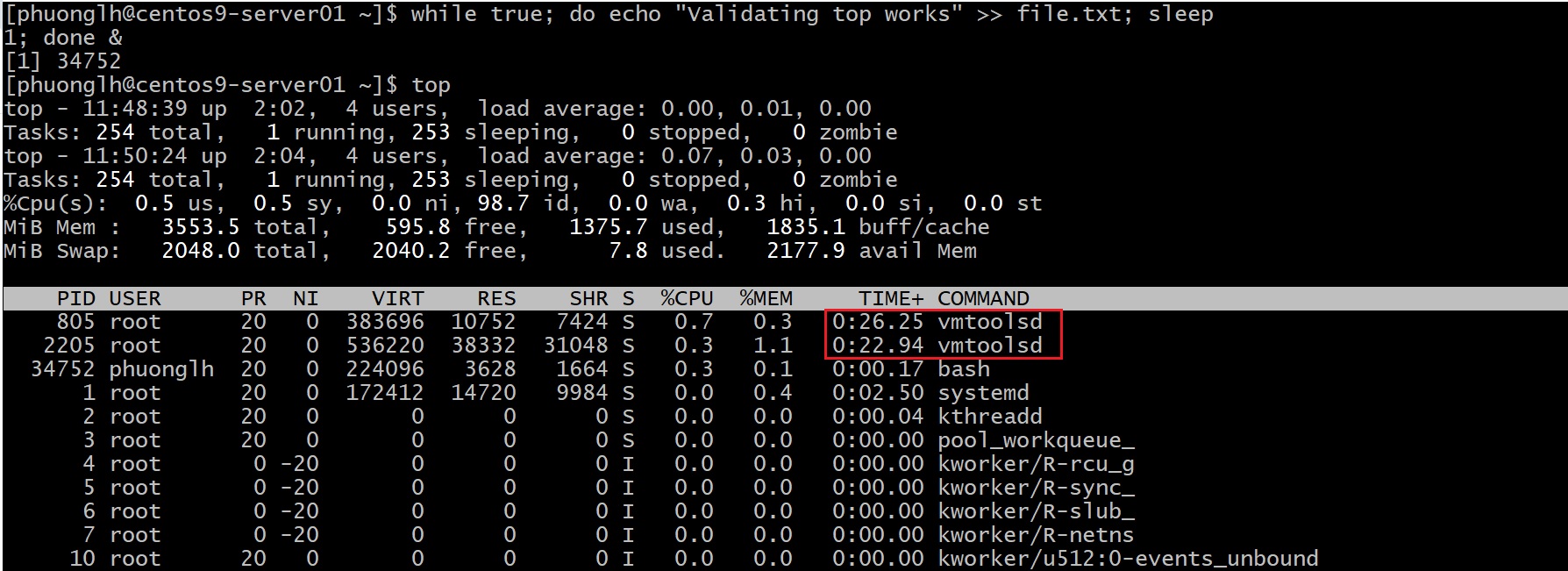
Giao diện trực quan hơn với htop
htop về cơ bản cũng hiển thị tiến trình như top nhưng có màu sắc với giao diện đẹp và cho phép điều hướng lên xuống bằng phím mũi tên. Nhiều sysadmin thích htop vì dễ nhìn và dễ lọc tiến trình hơn. Nếu RHEL 9 hoặc Centos 9 của bạn chưa có, cài đặt bằng lần lượt các lệnh sudo dnf install epel-release và sudo dnf install -y htop (hầu hết trên RHEL 9 có sẵn hoặc trong repo mặc định).
Chúng ta sẽ lặp lại bài tập trên với htop:
Trước hết, chạy lại lệnh while true để tạo tiến trình nền một lần nữa (nếu file.txt đã quá to, bạn có thể đổi tên file khác để tránh làm đầy ổ đĩa):
Nhớ ghi lại PID mới. Bây giờ khởi động htop và chỉ hiển thị các tiến trình thuộc user hiện tại (giả sử user đang dùng là your-user):
Tùy chọn -u <user> giúp lọc tiến trình theo user, rất tiện để tập trung vào process của mình (đặc biệt hữu ích trên server nhiều user chạy nhiều dịch vụ). Trong htop, dùng phím mũi tên xuống để chọn tiến trình “while true” (bạn sẽ thấy nó chạy bởi your-user, dùng CPU đều đặn). Khi đã bôi màu và chọn tiến trình đó, nhấn phím k (chữ thường, hoặc phím F9 cũng được). Htop sẽ hiện menu chọn tín hiệu kill tương tự như trên. Dùng phím mũi tên để chọn SIGKILL (9), rồi Enter. Tiến trình sẽ bị kill ngay lập tức. Thoát htop bằng cách nhấn Q (hoặc F10).
So với top, thao tác trên htop có thể nhanh hơn nhờ không cần nhớ PID và có giao diện menu. Dù bạn dùng công cụ nào, điều quan trọng là hiểu rõ hệ thống đang chạy gì, tốn bao nhiêu tài nguyên. Nếu server chậm mà bạn không mở nổi top/htop ra để xem, thì xin lỗi – bạn đang làm sai nghề rồi đấy .
Kiểm tra dung lượng ổ đĩa với df và du
CPU/RAM xong, giờ đến ổ đĩa. Hệ thống có thể chết cứng chỉ vì đầy disk, nên monitoring dung lượng disk là bắt buộc. Công cụ đơn giản nhất:
df (disk free).
Chạy lệnh sau để xem dung lượng các phân vùng (bao gồm tổng dung lượng, đã dùng, còn trống, % sử dụng, và điểm mount):
Tham số -h (human-readable) giúp hiển thị đơn vị dễ đọc (KB, MB, GB thay vì block 1K). Bạn sẽ thấy output liệt kê các mount point như /, /home, v.v. Ví dụ:
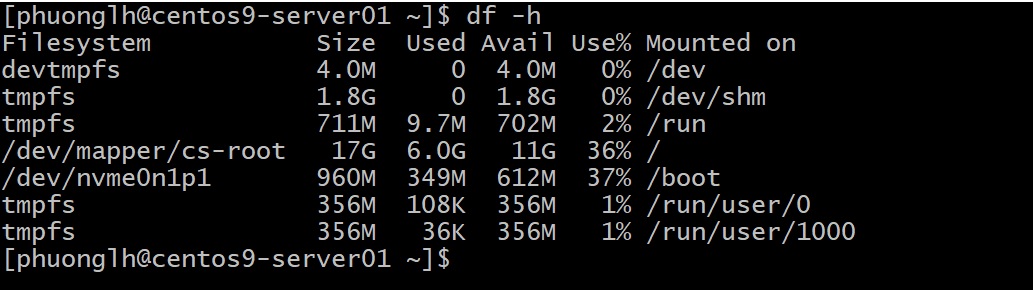
Nếu cột Use% gần 100% ở phân vùng nào, bạn có việc để làm ngay đấy: tìm xem cái gì chiếm dung lượng nhiều như vậy. Ở đây, lệnh du sẽ giúp đào sâu hơn.
du (disk usage) cho biết dung lượng của từng thư mục/files. Hãy thử kiểm tra dung lượng thư mục home của user (ví dụ your-user):
Trong đó:
-
-c(–-total): tính tổng dung lượng cuối cùng. -
-h(human-readable): hiển thị đơn vị dễ đọc. -
-s(summarize): chỉ hiển thị tổng dung lượng của thư mục chỉ định, kèm tổng các mục con.
Lệnh trên sẽ in dung lượng của toàn bộ thư mục /home/your-user và tổng kết dung lượng. Bạn có thể thay bằng bất kỳ thư mục nào mà bạn nghi ngờ để xác định thủ phạm gây đầy ổ đĩa. Ví dụ, nếu df cho thấy phân vùng gốc / đầy, hãy chạy du -h -d1 / để xem thư mục nào trong root lớn nhất (tùy chọn -d1 cho depth 1). Từ đó, đi sâu thêm vào thư mục lớn bất thường.
Mẹo cho sysadmin: Xóa file log cũ, file backup lỗi thời, hoặc cache linh tinh có thể giải phóng đống dung lượng. Nhưng trước khi xóa, nhớ xem kỹ bạn đang xóa cái gì kẻo “chữa lợn thành què” (cẩn thận kẻo xóa nhầm file config hay dữ liệu quan trọng). Luôn backup nếu có thể.
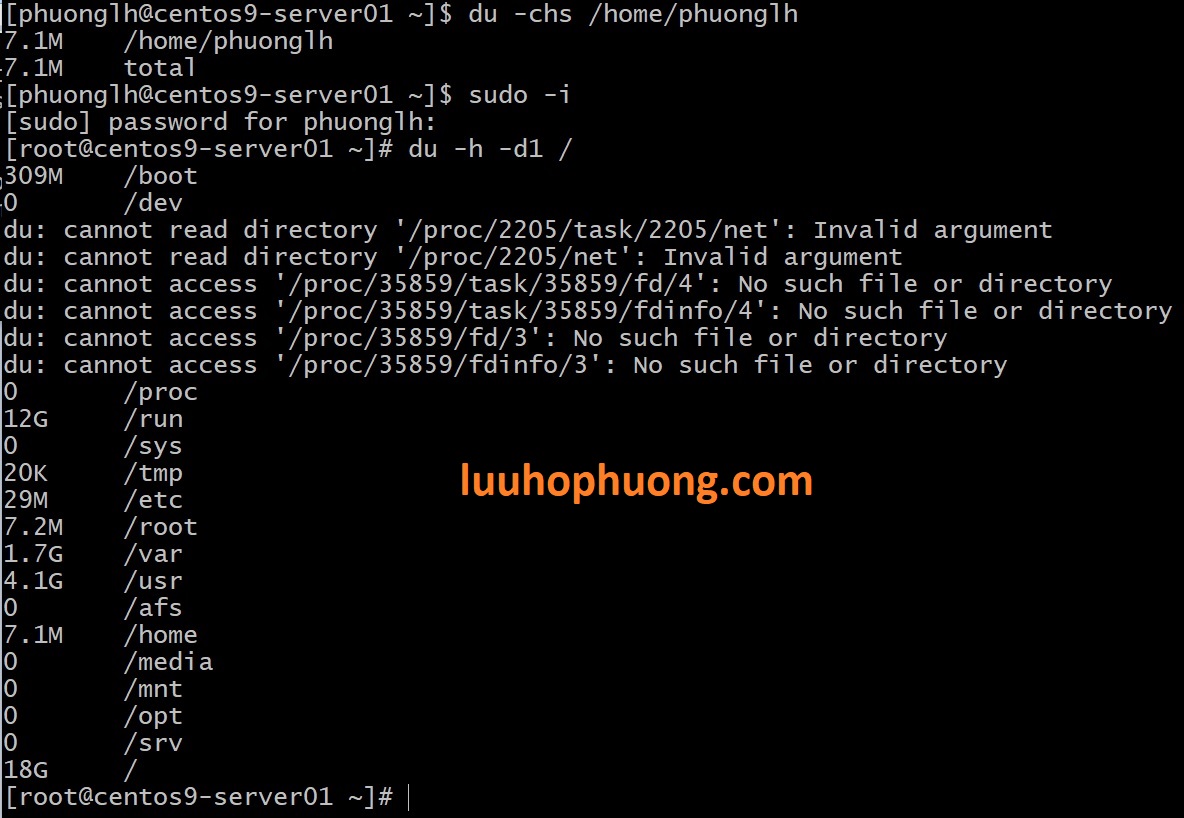
Phát hiện bottleneck (nút thắt cổ chai) CPU/RAM với vmstat
Cuối cùng, công cụ toàn cảnh cho hiệu suất hệ thống: vmstat (virtual memory statistics). Lệnh này cho bạn cái nhìn tổng quát về bộ nhớ, CPU, IO, swap… trong một bảng. Cú pháp đơn giản:
Tùy chọn -s liệt kê một loạt thống kê kể từ lần boot, ví dụ như tổng CPU time idle, số lần swap, v.v. Tuy nhiên, sức mạnh thật sự của vmstat nằm ở chế độ liên tục cập nhật. Thử chạy:
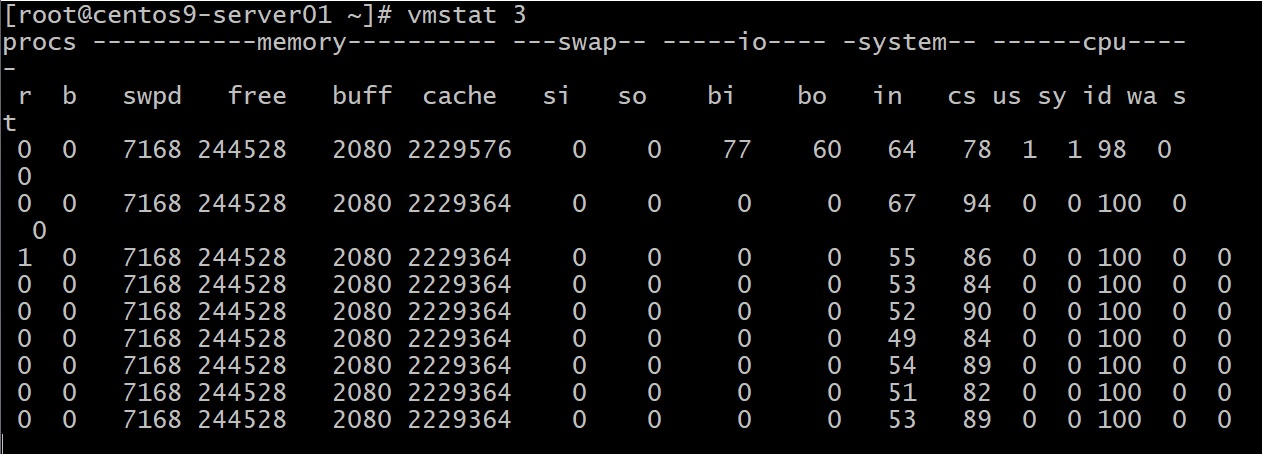
Lệnh trên sẽ hiển thị thống kê và cập nhật mỗi 3 giây (3 là khoảng delay, bạn có thể chọn 1, 5, tùy nhu cầu). Để dừng, nhấn Ctrl+C. Bạn sẽ thấy các cột như r, b (số tiến trình sẵn sàng chạy hoặc đang chờ), free (RAM trống), si/so (swap-in, swap-out), us, sy, id, wa (CPU user, system, idle, IO wait).
Nếu giá trị us (user CPU) + sy (system CPU) cao ngất ngưởng, mà id (idle) ~ 0%, nghĩa là CPU đang bị xài hết công suất. wa (IO wait) cao có thể do ổ đĩa chậm khiến CPU phải chờ. si/so > 0 liên tục chứng tỏ hệ thống đang thở oxy từ swap, có thể thiếu RAM nghiêm trọng. Tất cả những dấu hiệu này giúp bạn bắt mạch xem hệ thống đang nghẽn ở đâu (CPU, RAM hay IO).
Thực tế phũ phàng: Nếu
vmstatcho thấy CPU luôn 100%, load average cao ngất, và bạn đã tối ưu hết mức mà vẫn không thể cứu vãn hệ thống Linux, như vậy có lẽ đã đến lúc bạn phải móc hầu bao nâng cấp phần cứng hoặc scale-out. Monitoring là để biết giới hạn của hệ thống – đừng kỳ vọng nó sẽ phép màu tăng tài nguyên cho bạn.
Tóm lại, với top/htop, df/du, vmstat, bạn đã có bộ công cụ căn bản để giám sát Linux. Đây là những thứ phải thuộc nằm lòng trước khi nghĩ đến giải pháp phức tạp hơn. Giờ chuyển sang phần logs, một mảng thường bị các IT xem nhẹ cho đến khi sự cố xảy ra.
Thiết lập hệ thống Logging và Auditing
Nếu monitoring giúp bạn thấy điều gì đang xảy ra thì logging giúp bạn hiểu điều gì đã xảy ra. Nhật ký hệ thống (system logs) là nguồn thông tin quý giá để gỡ rối sự cố, theo dõi bảo mật (audit), và phân tích hành vi hệ thống. Một sysadmin lười biếng có thể bỏ mặc log, nhưng một sysadmin chuyên nghiệp phải biết tận dụng Linux system logging.
Trên RHEL (và hầu hết các distro hiện đại), hệ thống log gồm hai thành phần chính: systemd-journald (nhật ký nhị phân trong bộ nhớ/ổ đĩa) và rsyslog (dịch vụ ghi log truyền thống ra file text dưới /var/log/). Ngoài ra, ta có thể dùng các công cụ hỗ trợ như logwatch để tổng hợp log thành báo cáo hữu ích. Ở đây, chúng ta sẽ đảm bảo rsyslog chạy, học cách dùng journalctl để xem log, và cấu hình logwatch gửi báo cáo qua email. (Bạn nào thích có thể tìm hiểu thêm về auditd – nhưng trong phạm vi bài này, “auditing” chỉ là chủ động xem xét log thôi).
Kích hoạt và kiểm tra dịch vụ rsyslog
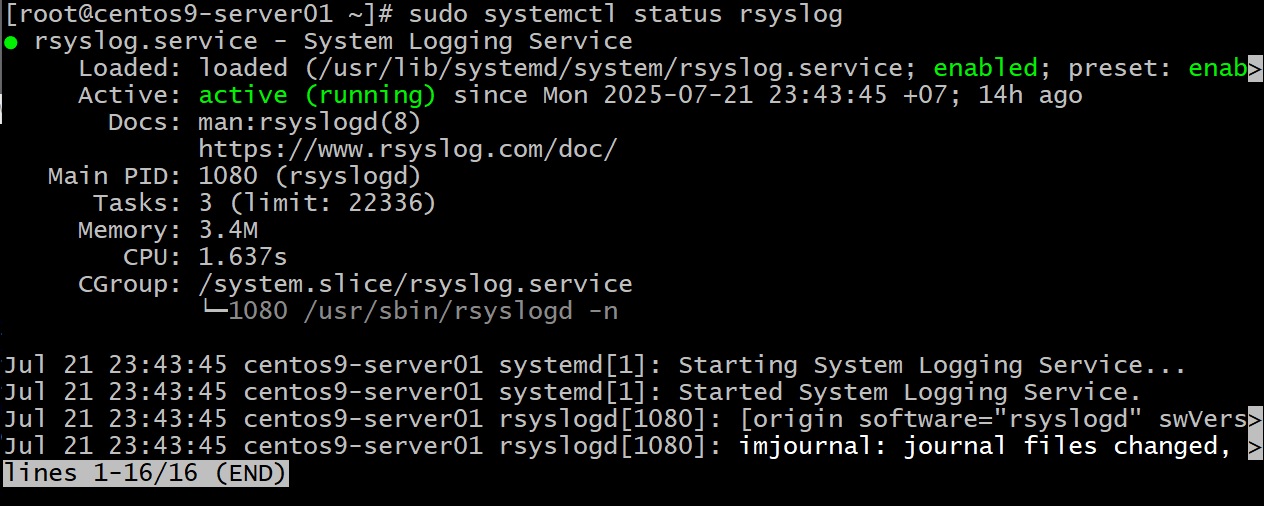
Đầu tiên, hãy chắc chắn rsyslog (trình quản lý log chính trên RHEL) đang chạy. Kiểm tra trạng thái dịch vụ:
Nếu kết quả cho thấy rsyslog inactive hoặc disabled, bạn cần bật nó lên:
Lệnh start khởi động ngay, enable để tự động khởi động cùng hệ thống Linux cho những lần sau. Thông thường trên RHEL 9, rsyslog mặc định đã chạy. Dù bạn có dùng hay không, đừng tắt nó trừ phi bạn có giải pháp log khác, vì thiếu logging khác nào bịt mắt bịt tai quản trị hệ thống.
Khi rsyslog chạy, nó sẽ liên tục ghi log từ systemd journal ra các file văn bản trong /var/log/. Ví dụ: log hệ thống chung trong /var/log/messages, log bảo mật trong /var/log/secure, v.v. Bạn có thể mở mấy file này ra xem, nhưng có cách hay hơn nhiều: dùng journalctl.
Xem log hệ thống với journalctl
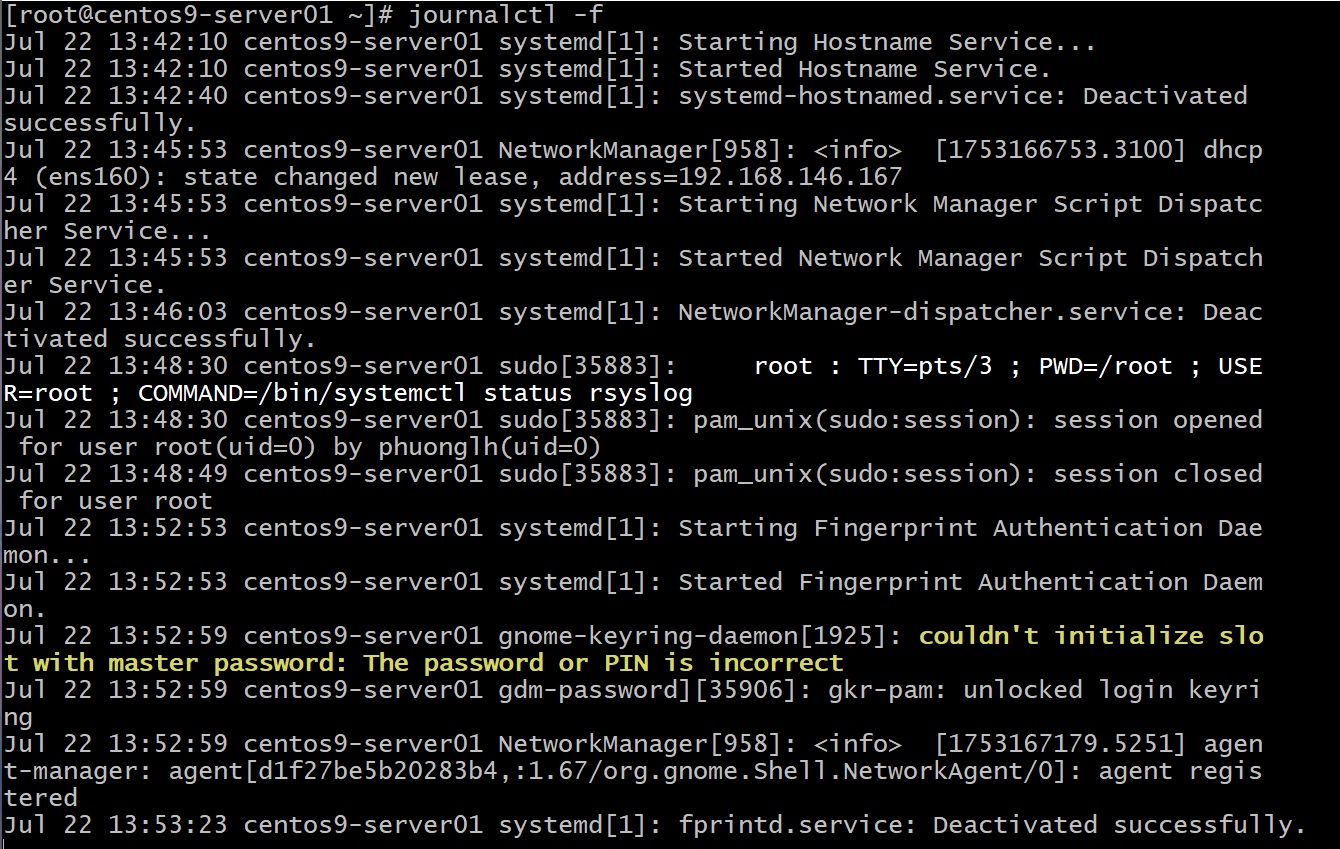
journalctl là công cụ dòng lệnh để đọc log từ systemd journal – nơi tập trung mọi log của hệ thống (kể cả những log chưa hoặc không được rsyslog ghi ra file). Nó linh hoạt và mạnh mẽ hơn lệnh tail -f /var/log/whatever cổ điển rất nhiều. Một số cách dùng thông dụng:
-
Xem toàn bộ log từ khi boot đến giờ (cảnh báo: có thể rất dài):
Cuộn lên/xuống để xem (nhấn
Qđể thoát). Bạn sẽ thấy log được sắp xếp theo thời gian, mới nhất ở cuối. Tất tần tật mọi sự kiện từ kernel, dịch vụ, ứng dụng… đều ở đây. Tốt cho forensic, nhưng để tìm nhanh thì cần lọc. -
Xem log chỉ của lần khởi động hiện tại (bỏ các log từ boot trước):
Tùy chọn
-b(boot) giúp thu hẹp log cho dễ xử lý, nhất là khi uptime dài. -
Lọc log theo đơn vị dịch vụ (systemd unit), ví dụ dịch vụ SSH (
sshd):Lệnh trên sẽ hiển thị tất cả log do service
sshdtạo ra (tương đương nội dung file/var/log/securenhưng đầy đủ hơn). Rất hữu ích khi bạn muốn soi một dịch vụ cụ thể mà không bị loãng bởi log khác. Thử thaysshdbằng tên dịch vụ khác nhưcron,nginx,cockpit… tùy nhu cầu. -
Bạn cũng có thể lọc theo thời gian, mức độ log (priority) v.v. Ví dụ: thêm
-p 3để chỉ xem log mức lỗi nghiêm trọng (ERR) trở lên, hoặc--since "2025-07-20"để xem từ ngày nhất định. Những tính năng này rất tiện khi truy vết sự cố.
Nói chung, journalctl là vũ khí lợi hại để đào bới log. Nó giúp việc audit hệ thống (kiểu xem ai làm gì, dịch vụ nào lỗi) trở nên hiệu quả hơn rất nhiều so với việc mở từng file log thủ công.
Mẹo: Nếu bạn chạy
journalctl -f, nó sẽ tail -f toàn bộ log giống như theo dõi real-time. Rất tiện để vừa thực hiện hành động (ví dụ restart dịch vụ) vừa coi log chạy gì ngay lập tức.
Tự động gửi báo cáo log với logwatch
Đọc log thì tốt, nhưng mỗi ngày ngồi xem cả mớ log thì không ai rảnh vậy. Đó là lý do có logwatch – một tiện ích tự động tổng hợp log thành báo cáo hằng ngày, thường gửi qua email cho admin. Báo cáo này tóm tắt những sự kiện đáng chú ý trong log (như số lần đăng nhập SSH, lỗi ứng dụng, v.v) để bạn không bỏ sót điều quan trọng.
Trên RHEL 9, gói logwatch có thể chưa được cài sẵn. Kiểm tra bằng cách:
Nếu không thấy kết quả, cài đặt nó (máy bạn cần có kết nối internet hoặc có sẵn repo):
Sau khi cài, file cấu hình mẫu nằm ở /usr/share/logwatch/default.conf/logwatch.conf. Mặc định, logwatch sẽ gửi mail đến root (hoặc alias của root) trên máy cục bộ. Bạn có thể chỉnh lại tham số MailTo trong file config để gửi đến email của bạn. (Thú thực, việc cấu hình SMTP gửi mail đôi khi lằng nhằng – nếu môi trường lab không gửi mail ra ngoài được thì cứ xuất báo cáo ra file HTML cho dễ xem).
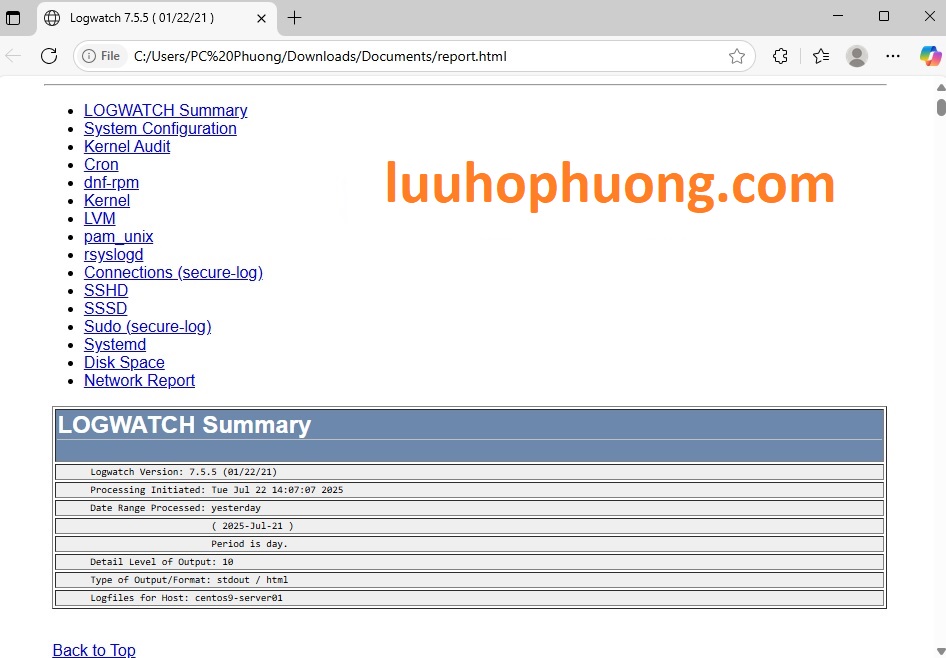
Để chạy thử logwatch và tạo báo cáo, dùng lệnh:
Giải thích các tùy chọn trên:
-
--detail high: Mức độ chi tiết cao (bạn có thể chọn low, med, high – tùy ý). -
--range 'yesterday': Phạm vi log là ngày hôm qua. Bạn có thể dùngtoday, hoặc khoảng thời gian cụ thể. -
--service all: Bao gồm tất cả các dịch vụ (logwatch có thể chọn báo cáo cho một số dịch vụ nhất định, ví dụ--service sshd). -
--format html: Định dạng đầu ra HTML (dễ đọc). Có thể chọn text, html, hoặc csv. -
>> report.html: Chuyển kết quả vào filereport.html.
Chạy xong, dùng ls để chắc file report.html đã được tạo. Bạn có thể mở file này bằng browser (nếu máy có giao diện) hoặc chuyển nó sang máy có GUI để mở. Báo cáo HTML sẽ trình bày đẹp mắt các mục: ví dụ Failed login attempts, Disk Space Usage (nếu có plugin), Services Errors… Mỗi sáng nhận được email báo cáo kiểu này sẽ giúp bạn sớm phát hiện bất thường thay vì đợi hệ thống toang.

Lưu ý: Triển khai
logwatchgửi mail trong thực tế đòi hỏi cần có máy chủ mail hoặc relay mail. Trong môi trường doanh nghiệp, hãy cấu hình SMTP chuẩn để logwatch có thể gửi email ra ngoài (hoặc tích hợp vào hệ thống SIEM). Còn ít nhất, chạy nó thủ công mỗi ngày cũng hơn là không bao giờ ngó log.
Đến đây, bạn đã có hệ thống logging cơ bản: dịch vụ log đang chạy, biết cách xem log thủ công và tự động. Bây giờ, chúng ta chuyển sang một “DevOps tool” xịn hơn để giám sát: Cockpit – Web Console chính chủ của RHEL.
Triển khai công cụ giám sát hệ thống: Cockpit (Web Console)
Không phải lúc nào bạn cũng muốn gõ lệnh để xem trạng thái của hệ thống Linux. Cockpit là một công cụ giao diện web do Red Hat phát triển, giúp bạn quản trị server Linux qua trình duyệt một cách dễ dàng. Cockpit trên RHEL 8/9 cho phép xem hiệu xuất của server linux theo real-time, quản lý dịch vụ, đăng nhập journal, thậm chí mở terminal ngay trong web. Nói cách khác, nó như một bảng điều khiển trực quan – DevOps tools for Linux kiểu mới. Hãy cùng cài đặt và khám phá Cockpit.
Cài đặt và kích hoạt Cockpit trên RHEL 9
Trên RHEL 9, Cockpit thường có sẵn trong repository chính. Trước hết, kiểm tra xem nó đã được cài chưa:
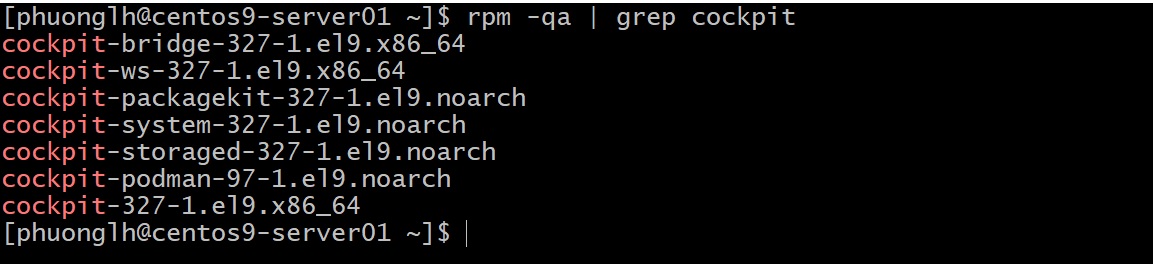
Nếu có kết quả (ví dụ gói cockpit-****), nghĩa là nó đã được cài. Nếu không, cài đặt nhanh bằng:
Sau khi cài xong (hoặc nếu có sẵn rồi), kích hoạt dịch vụ Cockpit:
Lệnh enable đảm bảo Cockpit tự chạy sau mỗi lần reboot, và start khởi động ngay bây giờ. Kiểm tra trạng thái để chắc chắn mọi thứ ổn:
Nếu mọi thứ đúng, bạn sẽ thấy trạng thái active (running) cho service cockpit.service. Mặc định, Cockpit chạy một web server lắng nghe trên cổng 9090. Chúng ta kiểm tra nhanh xem cổng 9090 đã mở chưa:
Kết quả sẽ hiện một dòng như *:9090 LISTEN kèm PID và tên chương trình (cockpit-ws) nếu Cockpit đang chạy. (Nếu lệnh netstat không có, cài net-tools hoặc dùng ss -ntlp tương đương).
Firewall: Đừng quên cấu hình firewall để mở cổng 9090 nếu firewall đang bật (trên RHEL dùng
firewalld). Ví dụ:sudo firewall-cmd --add-service=cockpit --permanent && sudo firewall-cmd --reload. RHEL thường có sẵn zone cho cockpit, nhưng bạn nên chắc chắn để có thể truy cập từ xa.

Truy cập Cockpit qua giao diện web
Đến giờ phút này, Cockpit đã chạy trên server. Hãy chuyển sang máy trạm của bạn (hoặc bất kỳ máy nào có trình duyệt web) để truy cập giao diện web. Mở trình duyệt và nhập địa chỉ:
(Ví dụ: nếu server RHEL có IP nội bộ 192.168.1.100, hãy dùng https://192.168.1.100:9090). Lưu ý Cockpit dùng HTTPS mặc định. Lần đầu truy cập, bạn sẽ thấy trình duyệt cảnh báo kết nối không an toàn do chứng chỉ tự ký (self-signed certificate). Trong môi trường lab hoặc nội bộ, bạn có thể bấm “Advanced” -> “Accept the risk and continue” (Chấp nhận rủi ro để tiếp tục). Dĩ nhiên, đừng làm thế trên môi trường internet/trong production nếu bạn không cài chứng chỉ SSL hợp lệ! Ở đây ta chấp nhận vì biết rõ server của mình.
Sau khi vượt qua cảnh báo, trang đăng nhập Cockpit hiện ra. Hãy nhập username và password của tài khoản trên server RHEL để login. Nếu Ở môi trường RHEL trên cloud (ví dụ AWS), user ec2-user thường không có password (chỉ dùng key SSH). Trong trường hợp đó, bạn cần đặt password cho nó trước bằng lệnh sau trên server RHEL:
Đặt một password tạm (vd: Passw0rd123 – đừng dùng password quá đơn giản trên server thật). Sau đó dùng tài khoản ec2-user và password vừa đặt để đăng nhập Cockpit. (Nếu bạn có quyền root và đã đặt mật khẩu cho root, bạn cũng có thể đăng nhập trực tiếp bằng tài khoản root).

Lưu ý: Nếu bạn login vào Cockpit và bị “Permission denied” khi đăng nhập Cockpit bằng tài khoản root là tình huống rất phổ biến trên các bản RHEL, CentOS, Rocky Linux, AlmaLinux, và lý do thường đến từ cấu hình trong file /etc/cockpit/disallowed-users, vì vậy bạn cần mở file này: .
sudo nano /etc/cockpit/disallowed-users
Và comment dòng này lại (thêm # phía trước) để cho phép root:
#root
Sau đó khởi động lại dịch vụ cockpit:
sudo systemctl restart cockpit
Khi đăng nhập thành công, Cockpit sẽ hiện một bảng điều khiển với thông tin tổng quan: CPU, Memory, Disk, Network… theo thời gian thực dưới dạng biểu đồ. Tuy nhiên, để thực hiện các tác vụ quản trị nâng cao (như xem log hệ thống, quản lý dịch vụ), bạn cần quyền admin. Nhìn góc trên bên phải (hoặc trong menu), bạn sẽ thấy nút “Turn on administrative access” (Bật quyền quản trị). Nhấn vào đó, Cockpit sẽ yêu cầu nhập lại password để xác nhận nâng quyền (thực chất là thực thi các lệnh với sudo). Sau khi xác thực, bạn có toàn quyền trong phiên Cockpit này.
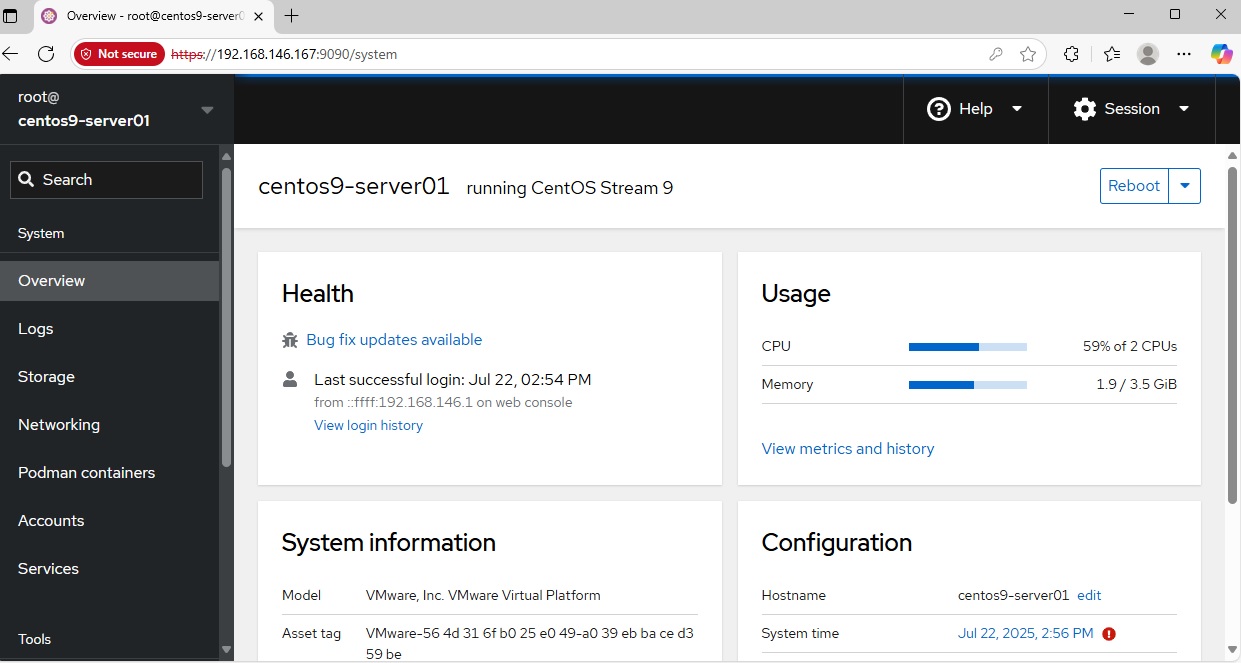
Giờ bạn có thể khám phá Cockpit:
-
Xem biểu đồ CPU, bộ nhớ, I/O theo thời gian thực trên trang Dashboard. Bạn sẽ thấy ngay khi CPU tăng, biểu đồ có thể chuyển màu (vàng/đỏ) nếu vượt ngưỡng – một dạng cảnh báo trực quan.
-
Vào mục Logs (Nhật ký): Cockpit tích hợp sẵn giao diện xem systemd journal. Bạn có thể lọc theo dịch vụ, khoảng thời gian, mức độ… tương tự
journalctlnhưng dễ dùng hơn. Đây là cách xem Linux system logging qua giao diện web, rất tiện khi bạn lười mở terminal. -
Vào Services để xem trạng thái các dịch vụ (systemd unit) và có thể khởi động/dừng chúng chỉ bằng nút bấm.
-
Mục Terminal cho phép bạn mở một phiên shell ngay trong trình duyệt, đề phòng bạn không muốn/không thể SSH nhưng vẫn cần gõ lệnh.
-
Ngoài ra, Cockpit có thể mở rộng với plugin (ví dụ plugin Docker/Podman để quản lý container, plugin Kubernetes, etc. Nhưng đó là chuyện khác).
Mẹo: Cockpit lý tưởng cho việc giám sát nhanh hoặc hỗ trợ quản trị cho người mới. Tuy nhiên, nó không thay thế hoàn toàn việc hiểu các lệnh nền tảng. Hãy coi Cockpit như một công cụ bổ trợ: khi bạn đã rành lệnh, Cockpit giúp tiết kiệm thời gian trong nhiều thao tác thường nhật.
Một câu hỏi thường gặp: Cockpit có gửi cảnh báo được không? Mặc định, Cockpit chủ yếu hiển thị thông tin và cảnh báo màu sắc trên giao diện. Nó chưa có chức năng gửi email hay thông báo ngoài (vì không phải hệ thống cảnh báo chuyên dụng). Tuy nhiên, bạn có thể tích hợp Cockpit với Prometheus hoặc sử dụng PCP (Performance Co-Pilot) kèm theo để thiết lập cảnh báo chi tiết hơn. Với nhu cầu vừa phải, việc thỉnh thoảng mở Cockpit xem cũng giúp bạn nắm tình hình, nhưng cho môi trường production lớn, nên triển khai giải pháp monitoring chuyên nghiệp như (Nagios, Zabbix, Prometheus+Grafana) để có alert gửi cho bạn khi bạn vắng mặt.
Tóm lại, bạn vừa bổ sung vào hệ thống của mình một công cụ Cockpit RHEL xịn xò. Giờ đến phần vui nhất: thử thách hệ thống và dùng tất cả những gì đã học để xử lý.
Thử thách cuối cùng: Mô phỏng hệ thống quá tải và xử lý
Đến đây, bạn đã học đủ chiêu thức, giờ là lúc thực hành tổng hợp. Chúng ta sẽ tạo một kịch bản stress test: giả lập máy chủ bị tải nặng trong ~10 phút và xem bạn ứng phó ra sao. Kịch bản này sẽ giúp kiểm chứng rằng monitoring & logging của bạn hoạt động hiệu quả.
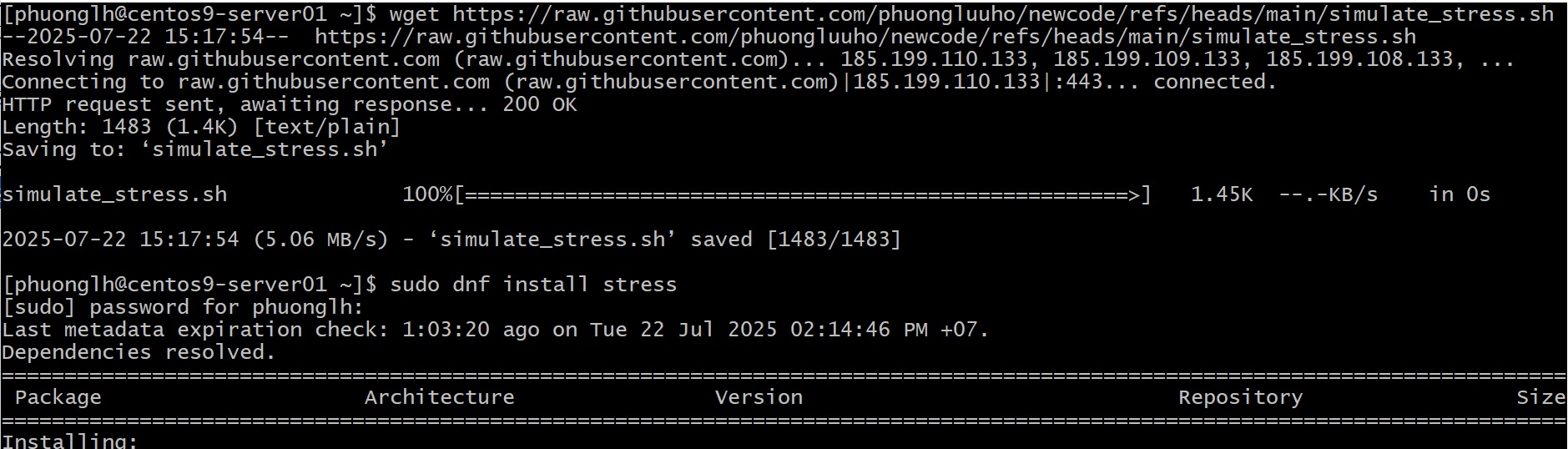
Bước 1: Mô phỏng stress hệ thống. Giả sử bạn có một script sẵn hãy download file script này về Linux server của bạn từ link: https://raw.githubusercontent.com/phuongluuho/newcode/refs/heads/main/simulate_stress.sh ( tên file là simulate_stress.sh) để làm nhiều thứ: chiếm CPU, ngốn RAM, ghi file đầy ổ đĩa, v.v. Chạy script này như sau:
Đầu tiên bạn cần cài đặt công cụ stress:
sudo dnf install stress
Nếu không sử dụng script trên, bạn có thể tự làm vài lệnh “phá hoại” như:
-
Chạy song song vài vòng lặp
while trueđể ăn CPU. -
Dùng
ddghi file lớn để nhanh đầy ổ:dd if=/dev/zero of=bigfile bs=1M count=100000(ghi ~100GB số 0 vào file bigfile). -
Chạy vài tiến trình tạo nhiều thread…
Nhưng hãy cẩn thận kẻo crash máy thật. Ở đây, chúng ta đã download script về thư mục home của user và Chạy nó:
Script bắt đầu hoạt động. Bạn có thể thấy máy bắt đầu đơ đơ nếu stress đủ mạnh. Trong khoảng 10 phút (hoặc tùy script), nó sẽ làm khổ CPU, RAM, Disk. Trong lúc đợi, tranh thủ đi pha cốc cà phê rồi quay lại chiến đấu tiếp.
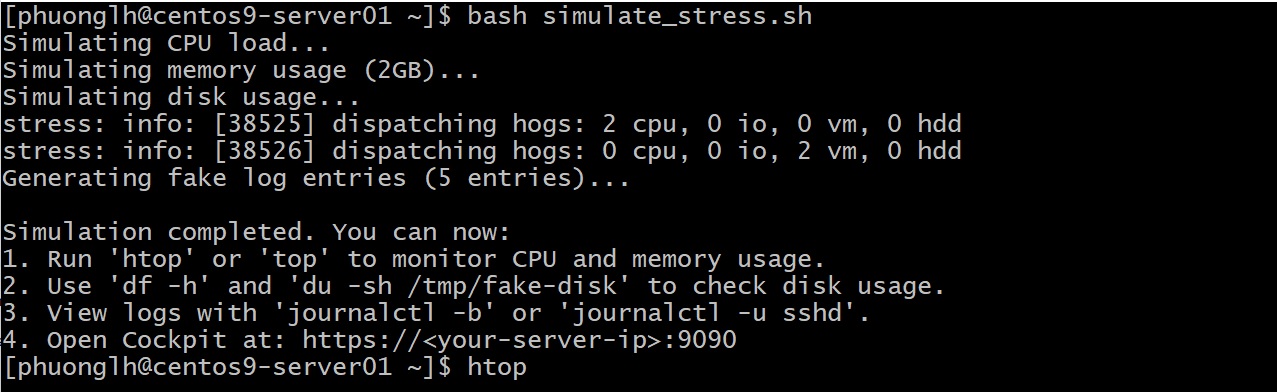
Bước 2: Quan sát hiệu ứng của stress bằng các công cụ đã học. Đây là trọng tâm – xem bạn có phát hiện kịp các dấu hiệu nguy hiểm không:
-
Kiểm tra CPU, RAM: Mở
tophoặchtop. Bạn gần như chắc chắn sẽ thấy 1 hoặc nhiều tiến trình đang chiếm 100% CPU (có thể tên làsimulate_stress.shhoặc những gì script gọi, ví dụyes > /dev/null,dd, v.v.). Load average có thể tăng vọt. RAM có thể bị chiếm đáng kể (nếu script allocate memory). Nếu CPU/RAM đầy, đây là dấu hiệu quá tải rõ rệt. Lúc này,vmstat 3cũng sẽ cho thấyus100%,id0%, có thểsi/so> 0 nếu swap xảy ra. Bottleneck CPU/RAM đã rõ mồn một. -
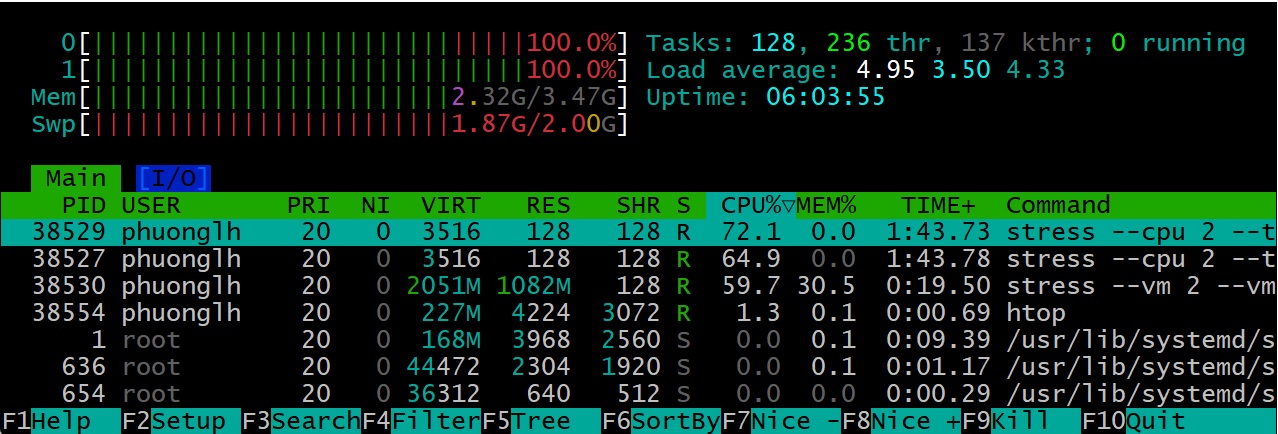
Kiểm tra ổ đĩa: Chạy
df -hđể xem phân vùng nào gần đầy. Nếu script có tạo file lớn, có thể phân vùng/hoặc/homesẽ từ chỗ trống biến thành 100% rất nhanh. Ví dụ, thấy/nhảy lên 100% Used, nghĩa là disk full sắp xảy ra (nếu chưa xảy ra). Tiếp theo, dùngduđể truy tìm thủ phạm:-
Nếu
/đầy, chạydu -sh /*(như root) để xem thư mục nào phình to nhất. -
Có thể bạn sẽ thấy
/home/your-user/system-stressdung lượng khủng. Hãy đào sâu:du -sh /home/your-user/system-stress/*để xem file nào to. -
Rất có thể script đã tạo file
bigfilevài chục GB như ví dụ. Xóa file đó đi (sau khi dừng script) sẽ giải phóng dung lượng. Nhưng trước khi xóa, nhớ dừng các tiến trình đang ghi file, kẻo chúng lại tạo tiếp. -
Song song,
vmstatcho thấy cộtwa(IO wait) cao bất thường nếu ổ đĩa bị ghi cật lực, và có khả năng CPUidcũng thấp vì CPU chờ IO.
-
-
Kiểm tra dịch vụ hệ thống: Stress cao có thể làm một số dịch vụ bị ảnh hưởng. Chẳng hạn, nếu CPU quá 100% liên tục, tiến trình
sshd(SSH server) có thể bị treo hoặc quá thời gian phục vụ yêu cầu. Hãy kiểm tra nhanh:-
systemctl status sshdxem SSH cònactivekhông (thường vẫn active, nhưng có thể ghi log thông báo). -
systemctl status rsyslogđể chắcrsyslogvẫn chạy (nếu máy cực kỳ lag, đôi khi syslog có thể tụt lại, nhưng hiếm khi chết). -
Nói chung, verify logging is active tức đảm bảo các thành phần giám sát cũng còn sống. Nếu
rsysloghaycockpitcũng chết theo thì tệ – nhưng may là thường chúng chịu được.
-
-
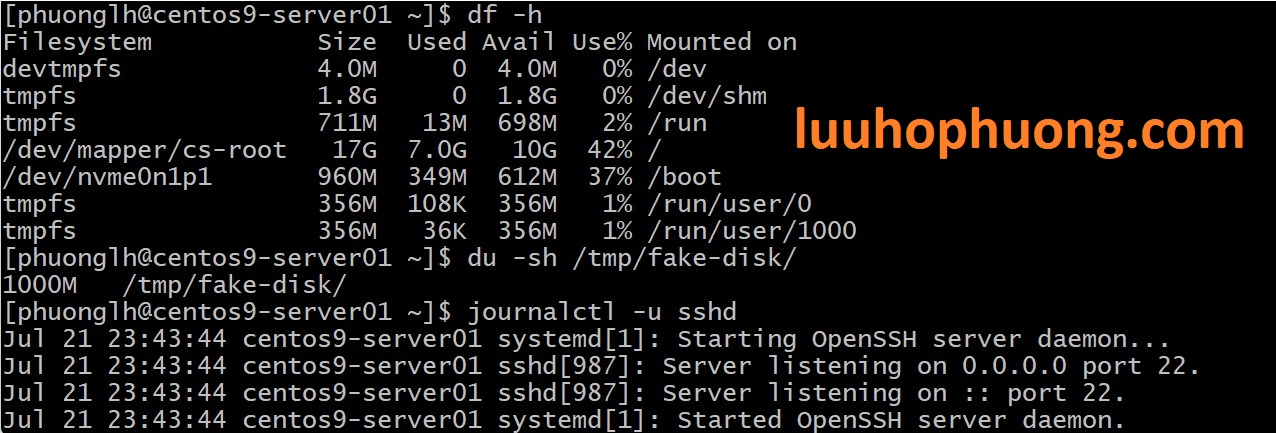
Xem log để tìm lỗi: Bây giờ, dùng
journalctlđể xem có lỗi nào xuất hiện trong giai đoạn stress:-
Thử
journalctl -p 3 -S "-5 minutes"(log mức err trong 5 phút gần nhất) xem có gì đỏ không. Hoặc đơn giảnjournalctl -u sshd -bxem log SSH: rất có thể có các dòng như “Disconnected: Too many authentication failures” hoặc lỗi time out nếu script cố mở nhiều kết nối (nếu script không đụng đến SSH thì log sshd không nhiều thay đổi). -
Xem log kernel:
journalctl -k -bđể xem kernel có kêu ca gì không (ví dụ OOM Killer có thể ra tay nếu hết RAM: bạn sẽ thấy log “Out of memory, kill process X”). -
Chạy lại
logwatchđể tạo báo cáo log cho khoảng thời gian stress (ví dụ--range 'since 1 hour ago'nếu logwatch cho phép, hoặc chờ đến ngày hôm sau báo cáo sẽ liệt kê). Báo cáo này có thể chỉ ra số lượng lớn thông báo lỗi, hay hoạt động bất thường trong khoảng đó.
Nói chung, audit log kỹ sau sự cố giúp bạn hiểu chuyện gì đã xảy ra. Ở đây chúng ta biết rõ do script cố tình, nhưng trên thực tế, những dấu hiệu như SSH login failures hàng loạt có thể là tấn công brute force, ổ đĩa đầy do log phát sinh quá mức hoặc ai tải nhầm file quá to, CPU 100% do tiến trình lỗi chạy loop… Tất cả đều sẽ để lại manh mối trong log.
-
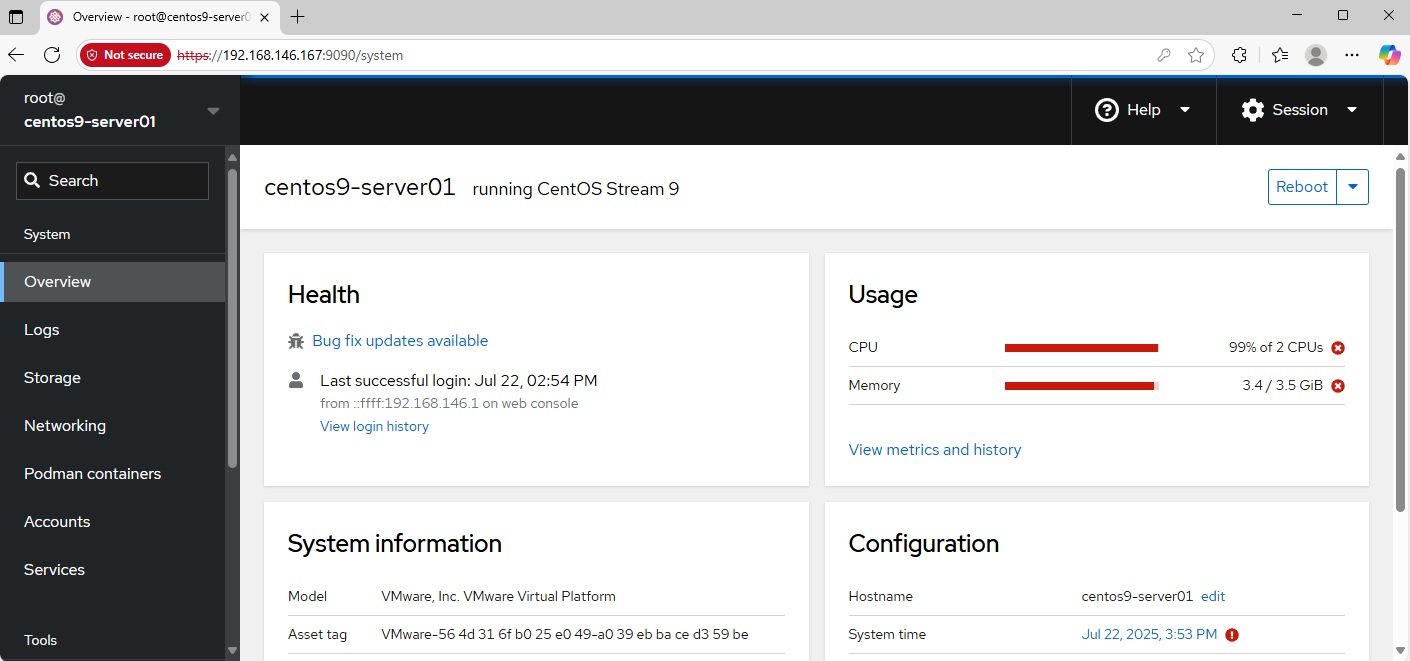
-
Quan sát Cockpit: Nếu bạn mở Cockpit trong lúc stress (giả sử máy còn phản hồi nổi), bạn sẽ thấy giao diện đổi khác:
-
Biểu đồ CPU có thể đỏ rực ở 100%, Memory chạm đỉnh, Disk I/O tăng cao.
-
Cockpit có thể đánh dấu cảnh báo (warning) cạnh các mục tài nguyên nếu quá ngưỡng (ví dụ CPU > 90%).
-
Bạn có thể vào mục Logs trên Cockpit để xem ngay các lỗi (cũng chính là journal, nhưng có thể lọc nhanh theo mức độ).
-
Ở Cockpit, bạn cũng có thể thiết lập thông báo nếu cài thêm plugin hoặc tích hợp. Nhưng mặc định, hãy để ý các chỉ số màu đỏ – đó cũng là cảnh báo rồi.
-
-
Thiết lập cảnh báo (tùy chọn): Như đã nói, Cockpit không gửi email alert sẵn. Nhưng bạn có thể:
-
Cài plugin cockpit-pcp để lưu trữ số liệu và có thể đặt ngưỡng cảnh báo trong giao diện (PCP cho phép thiết lập một số alerts cơ bản).
-
Hoặc tích hợp với các hệ thống khác: ví dụ, xuất số liệu Cockpit (từ PCP) ra Grafana và dùng Alertmanager để gửi thông báo khi vượt ngưỡng CPU, disk… (đây là nâng cao, vượt ngoài phạm vi bài viết).
-
Ở mức đơn giản: hãy tạo thói quen kiểm tra Cockpit hoặc các bảng giám sát hàng ngày. Nếu thấy màu đỏ hoặc bất cứ thứ gì bất thường, đừng lờ đi.
-
Bước 3: Kết thúc stress test. Sau khoảng 10 phút (hoặc khi bạn thấy đủ), dừng script stress (nếu nó không tự dừng):
-
Dùng
top/htopkill các tiến trình stress còn chạy. -
Xóa các file tạm khổng lồ mà script tạo ra (để giải phóng disk).
-
Quan sát hệ thống trở về trạng thái bình thường trên Cockpit (CPU drop, load giảm, …).
Bạn vừa hoàn thành một “diễn tập” sự cố. Nếu bạn theo dõi được mọi chỉ số, nhận ra vấn đề ngay và xử lý nhanh gọn (kill process, xóa file, v.v), thì xin chúc mừng: khả năng monitoring/logging của bạn khá tốt đấy. Còn nếu bạn hoảng loạn khi CPU đụng trần, hoặc không hiểu log báo gì, thì vẫn tốt – vì ít nhất bạn biết mình còn thiếu gì để học, hơn là để đến khi sự cố thật xảy ra mới cuống cuồng cả lên.
Kết luận: Không monitoring, không DevOps
Qua bài hướng dẫn dài hơi này, hy vọng bạn đã nắm được cách triển khai một hệ thống monitoring và logging căn bản trên RHEL/CentOS. Từ việc theo dõi CPU, RAM, disk real-time bằng công cụ cổ điển, đến quản lý log Linux bằng rsyslog, journalctl, và tự động hóa báo cáo với logwatch, rồi trải nghiệm Cockpit RHEL như một giải pháp trực quan, bạn đã có đủ vũ khí để quản trị hệ thống Linux chủ động hơn. Không còn lý do gì để “mù thông tin” về server của mình nữa – nếu server gặp sự cố bất ngờ, lỗi có lẽ nằm ở con người chứ không phải công cụ.
Hãy luôn nhớ: monitoring không ngăn được sự cố, nhưng giúp bạn phát hiện sớm và giảm thiểu thiệt hại. Logging không tự sửa được lỗi, nhưng cung cấp manh mối để bạn hiểu và khắc phục vấn đề, đồng thời hỗ trợ điều tra bảo mật. Trong thời đại DevOps hiện nay, monitoring và logging là những thành phần cốt lõi – thiếu nó thì đừng nói chuyện CI/CD hay Kubernetes cao siêu gì cả.
Cuối cùng, một chút chia sẻ thẳng thắn: nếu bạn (hoặc doanh nghiệp của bạn) cảm thấy choáng ngợp với việc tự xây dựng hệ thống monitoring/logging, đừng ngại nhờ giúp đỡ. Có rất nhiều chuyên gia và dịch vụ sẵn sàng hỗ trợ:
-
Chúng tôi cung cấp các khóa đào tạo Linux từ cơ bản đến nâng cao, giúp đội ngũ của bạn nắm vững kỹ năng quản trị hệ thống và DevOps.
-
Dịch vụ tư vấn DevOps của chúng tôi sẽ giúp bạn thiết kế một kiến trúc giám sát, logging bài bản, phù hợp quy mô doanh nghiệp (từ giải pháp nguồn mở đến thương mại).
-
Chúng tôi cũng nhận triển khai trọn gói hệ thống monitoring cho doanh nghiệp, tích hợp cảnh báo thông minh, dashboards tùy biến, đảm bảo bạn luôn kiểm soát được sức khỏe hạ tầng của mình.
Nếu bạn không muốn nửa đêm phải mò mẫm log hay đoán mò khi server gặp sự cố, hãy để đội ngũ chuyên nghiệp hỗ trợ. Liên hệ với chúng tôi để được tư vấn miễn phí về giải pháp giám sát hệ thống và đào tạo DevOps phù hợp nhất cho nhu cầu của bạn.
Tóm lại: Monitor thường xuyên, đọc log chăm chỉ, hệ thống của bạn sẽ vận hành trơn tru hơn và bạn sẽ ngủ ngon hơn. Còn nếu bỏ bê, sớm muộn gì bạn cũng nhận một bài học nhớ đời – khi đó, hy vọng hướng dẫn này sẽ giúp bạn cứu vãn tình hình. Chúc bạn giám sát hệ thống thành công và đừng quên luôn học hỏi thêm, vì thế giới Linux luôn đổi mới không ngừng.
#LinuxMonitoring #SystemPerformance #LinuxPerformance #MonitorLinux #LinuxTools #LinuxAdmin #DevOpsTools #SystemResourceMonitor #LinuxCommandLine #OpenSourceMonitoring##ITInfrastructure #SysAdminLife #DevOpsJourney #LinuxTips #MonitoringTools