
Contents
- 1 Giới thiệu
- 2 ⚙️ Tổng quan kiến trúc hệ thống
- 3 Thiết lập ban đầu
- 4 Cài đặt DRBD và phần mềm cluster
- 5 Cấu hình DRBD
- 6 Tạo filesystem và mount
- 7 Mục tiêu
- 8 Cấu hình Pacemaker + Corosync trên cả 2 nodes
- 8.1 Cấu hình Corosync
- 8.2 Cấu hình tài nguyên Cluster bằng Pacemaker
- 8.3 Kích hoạt hệ thống
- 8.4 ✅ Kiểm tra tình trạng hoạt động của cluster sau khi hoàn thành cấu hình
- 8.5 Kiểm thử failover
- 8.6 Một số lệnh dùng cho troubleshooting.
- 8.7 ✅ Giải pháp: Gỡ hoàn toàn DRBD device cũ và khởi tạo lại, trong trường hợp xác định lỗi không sync được data giữa 2 nodes.
- 8.7.1 Bước 0: Dừng mọi tiến trình liên quan (chắc chắn cả DRBD và mount)
- 8.7.2 Bước 1: Gỡ DRBD device khỏi kernel
- 8.7.3 Bước 2: Xóa metadata cũ trên disk
- 8.7.4 ✅ Bước 3: Tạo lại metadata từ đầu
- 8.7.5 Bước 4: Tải lại module và khởi động DRBD
- 8.7.6 Bước 5: Thiết lập lại kết nối
- 8.7.7 Bước 6: Kiểm tra trạng thái
- 8.8 Các chế độ lỗi
- 8.9 Kết luận
Giới thiệu
Với các doanh nghiệp nhỏ, chi phí luôn là yếu tố được cân nhắc hàng đầu. Tuy nhiên, điều đó không có nghĩa là bạn phải đánh đổi tính ổn định và tính sẵn sàng của hệ thống. Thay vì đầu tư vào những thiết bị SAN/iSCSI đắt tiền hay sử dụng các giải pháp thương mại phức tạp, bạn có thể xây dựng một cụm máy chủ High Availability (HA) mạnh mẽ và ổn định bằng phần mềm mã nguồn mở: Pacemaker, Corosync, DRBD và NGINX.
Trong mô hình HA shared-nothing, hai máy chủ hoạt động độc lập sao chép dữ liệu trực tiếp với nhau qua mạng mà không cần một thiết bị lưu trữ dữ liệu chung đắt tiền như SAN. DRBD (Distributed Replicated Block Device) chính là giải pháp mirror dữ liệu qua mạng theo kiểu RAID1, cho phép dùng phần cứng thông thường (commodity) để tạo cluster HA với chi phí thấp, chúng ta có thể thiết lập Nic Teaming ví dụ nếu mỗi một server có 2 cards tốc độ 1 Gbs thì có thể teaming 2 cards thành 2 Gbps để dành cho việc sao chép dữ liệu tốc độ cao giữa 2 servers. Và khi một máy chủ (Primary) đang hoạt động gặp sự cố, DRBD đảm bảo dữ liệu đồng bộ đã có sẵn trên node còn lại (Secondary), giúp khôi phục dịch vụ gần như ngay lập tức. Pacemaker và Corosync được sử dụng để quản lý tài nguyên (như IP ảo hay dịch vụ NGINX) trên cluster, tự động chuyển đổi vai trò khi cần thiết. Trong hướng dẫn này chúng ta sẽ xây dựng cluster HA kiểu Active-Passive trên Ubuntu Server 24.04, mỗi node có hai ổ đĩa (một ổ cho hệ điều hành, một ổ cho DRBD), IP tĩnh, và đảm bảo thứ tự khởi tạo: DRBD → FileSystem → VIP → NGINX
Giải pháp này sẽ giúp hệ thống web của bạn:
-
Tự động chuyển đổi sang node khác khi có sự cố.
-
Luôn sẵn sàng phục vụ người dùng.
-
Đồng bộ dữ liệu thời gian thực mà không cần dùng SAN.
⚙️ Tổng quan kiến trúc hệ thống
| Thành phần | Thông số |
|---|---|
| Node1 | /dev/sdb → DRBD → /dev/drbd0 |
| Node2 | /dev/sdb → DRBD → /dev/drbd0 |
| VIP | 192.168.146.100 (địa chỉ IP ảo cho client truy cập) |
| NIC External | ens33 (192.168.146.11 – node1, 192.168.146.12 – node2). |
| NIC Internal | ens37 (10.10.10.1 – node1, 10.10.10.2 – node2) |
Cluster HA sử dụng 2 NIC:
-
NIC ngoài (external) để client truy cập.
-
NIC nội bộ (internal) dành riêng cho DRBD replication (sao chép) dữ liệu giữa 2 servers tốc độ cao.

Thiết lập ban đầu
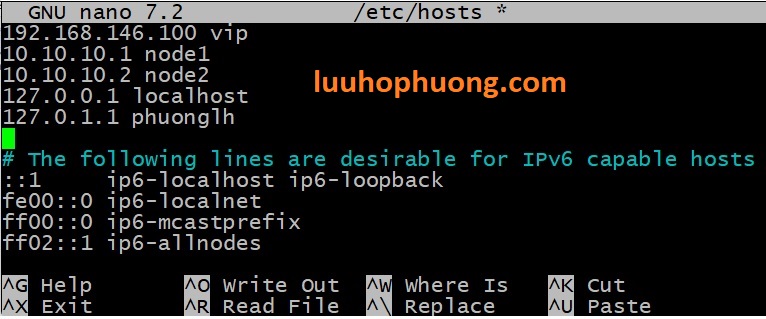
1. Đặt hostname và chỉnh sửa /etc/hosts với nội dung như sau.
Trên node1:
Trên node2:
Cập nhật /etc/hosts trên cả hai node:
2. Mở các cổng firewall cần thiết cho HA Cluster
Thực hiện trên cả hai node:
Cài đặt DRBD và phần mềm cluster
1. Cài DRBD 9 trên cả hai node
Đầu tiên, LINBIT PPA cần được cấu hình trên cả 2 nodes :
sudo add-apt-repository -y ppa:linbit/linbit-drbd9-stackLƯU Ý: LINBIT PPA là repo cộng đồng . Nó hơi khác so với các repo dành cho khách hàng LINBIT. PPA được dùng cho mục đích thử nghiệm và đánh giá.

✅Giải thích:
-
Mục đích: Thêm kho phần mềm (PPA) từ nhà phát triển LINBIT – nơi cung cấp các gói DRBD mới nhất.
-
DRBD (Distributed Replicated Block Device): Là phần mềm giúp đồng bộ dữ liệu ổ đĩa giữa 2 máy chủ theo thời gian thực (block-level).
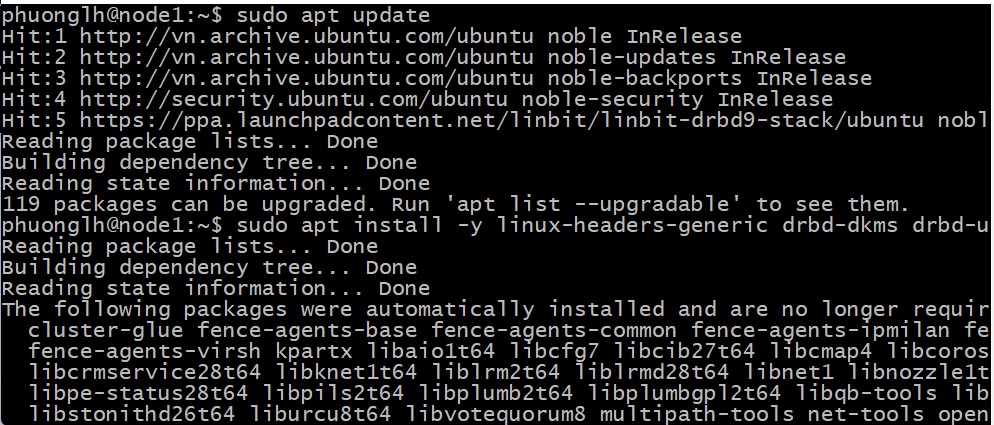
Cài đặt kernel headers để builddrbd-dkms package, và DRBD package:
sudo apt update
Khởi động lại cả hai nodes trước khi setup DRBD :
sudo reboot
sudo apt install -y linux-headers-generic drbd-dkms drbd-utils
sudo modprobe drbd && modinfo drbd
✅ Giải thích:
-
modprobe drbd: Nạp module DRBD vào kernel. -
modinfo drbd: Kiểm tra thông tin về moduledrbdvừa nạp (phiên bản, vị trí, license…)
2. Cài Pacemaker, Corosync, NGINX
⚠️ Lưu ý: từ Ubuntu 24.04 trở đi,
crmshkhông còn cài theopacemaker, bạn cần cài thủ công như trên.Pacemaker là công cụ quản lý dịch vụ trong HA Cluster, giúp tự động chuyển đổi (failover) khi một node gặp sự cố.
Corosync giữ vai trò liên lạc giữa các node, nó giúp biết node nào đang hoạt động và node nào bị lỗi. Cả hai cái này kết hợp với nhau tạo nên hệ thống High Availability đảm bảo dịch vụ luôn sẵn sàng.
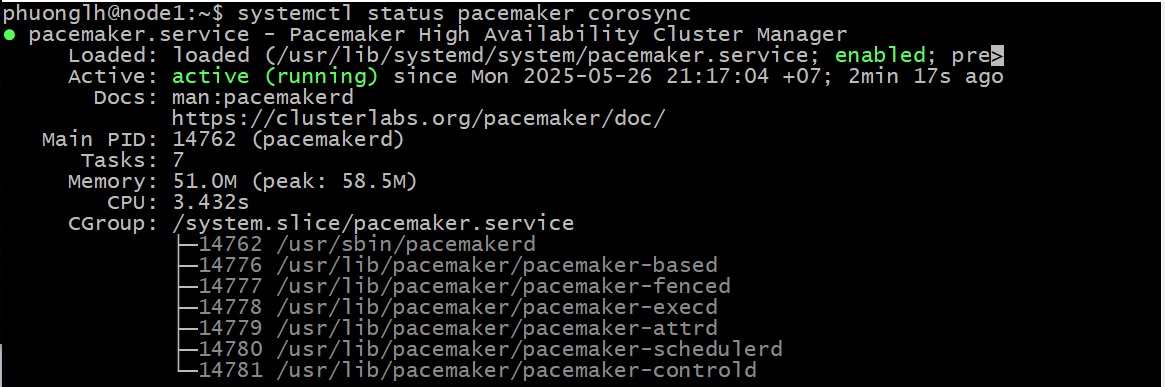
Sau khi cài đặt, cả pacemaker.service và corosync.service systemd services đều được bật và đang chạy. Xác minh điều này bằng cách chạy lệnh systemctl status pacemaker corosync.
Sau khi setup NGINX và xác minh rằng nó đang chạy trên cả hai nodes, dịch vụ NGINX cần phải được stop và disable trước khi cấu hình Pacemaker, chạy lệnh sau trên cả 2 nodes:
sudo systemctl disable --now nginx.service

Cấu hình DRBD
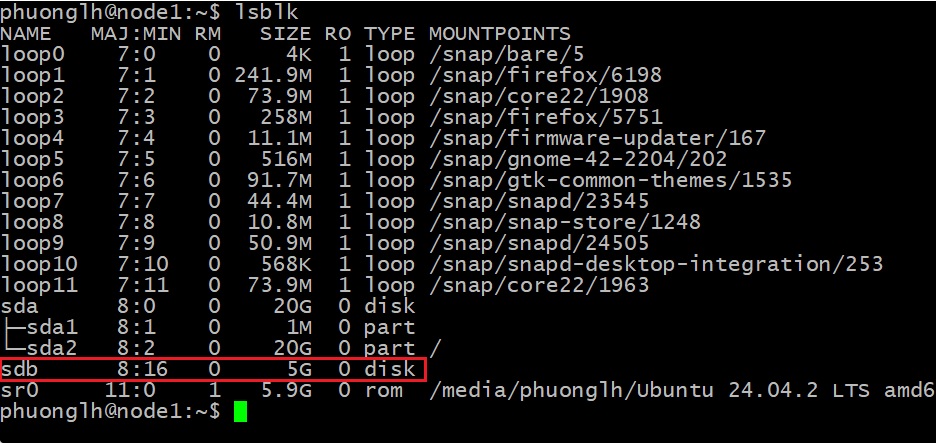
1. Chuẩn bị disk, thực hiện trên cả hai nodes.
Chay lệnh để xem các disks có trong server sử dụng lệnh:
lsblk
Có thể trong server của bạn có disk tên là sdb ( Lưu ý: nếu bạn gắn 1 disk vào server của bạn, có thể nó sẽ có 1 cái tên khác ).
sudo parted -s /dev/sdb mkpart primary 1MiB 100%

3. Khởi tạo và kích hoạt DRBD
Tạo metadata cho các tài nguyên DRBD. Bước này phải được thực hiện trên cả hai nodes:
MẸO: Để biết hướng dẫn chi tiết hơn về cấu hình ban đầu, vui lòng xem phần “Cấu hình DRBD” của Hướng dẫn sử dụng DRBD. Tạo siêu dữ liệu cho các tài nguyên DRBD. Bước này phải được thực hiện trên cả hai nodes:
sudo drbdadm create-md ha
Đưa tài nguyên lên cả 2 nodes.
sudo drbdadm up ha
Tài nguyên NGINX DRBD phải ở trạng thái connected và Secondary trên cả 2 nodes. Một trạng thái Inconsistent disk state được thấy . Xác minh trạng thái hiện tại của tài nguyên DRBD bằng cách chạy drbdadm status trên bất kỳ node nào. kết quả sẽ hiển thị thông tin trạng thái sau:

DRBD cần khởi tạo đồng bộ hóa đầy đủ hoặc đối với các tài nguyên hoàn toàn mới không có dữ liệu hiện có, bạn có thể bỏ qua đồng bộ hóa ban đầu bằng cách sử dụng tùy chọn –clear-bitmap. Chỉ chạy lệnh sau trên một node, ví dụ chạy lệnh trên node1:
sudo drbdadm --clear-bitmap new-current-uuid ha/0
LƯU Ý: **/0** ở cuối lệnh trên là để chỉ định số lượng disks của tài nguyên. Mặc dù ví dụ trên sử dụng một disk duy nhất, vẫn cần phải chỉ định số lượng disks, 0 là mặc định.
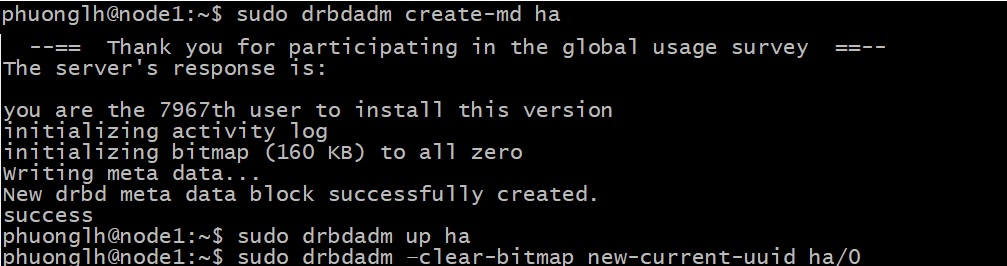
Tài nguyên NGINX DRBD bây giờ sẽ hiển thị disk là UpToDate trên cả hai nút. Xác minh trạng thái bằng cách chạy lại lệnh drbdadm status. Output từ lệnh bây giờ sẽ hiển thị:
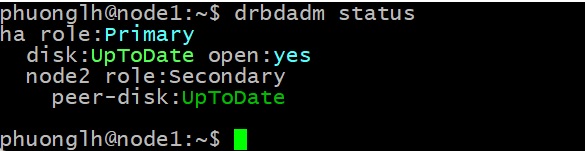
Tạo filesystem và mount
Sau khi tài nguyên DRBD đã được tạo và khởi tạo, bạn có thể tạo file system trên DRBD block device mới (/dev/drbd0). Chỉ tạo file system ext4 trên node1, sử dụng lần lượt các lệnh sau:
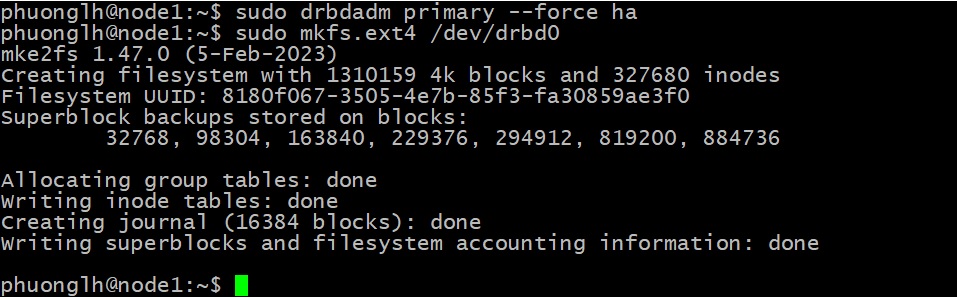
Cấu hình thư mục dữ liệu cho NGINX, chỉ thực hiện các việc này trên node1
Mục tiêu
-
Toàn bộ files dữ liệu, cấu hình và logs NGINX sẽ được lưu trữ trên DRBD (
/dev/drbd0) -
DRBD được mount vào một thư mục an toàn ngoài web root
-
NGINX vẫn hoạt động bình thường với symlink → DRBD
✅ Giải pháp an toàn (Khuyến nghị)
1. Mount DRBD trong thư mục riêng, chúng ta tạo thư mục /mnt/drbdvà mount thư mục (chỉ chạy lệnh này trên node1):
sudo mkdir /mnt/drbd && sudo mount /dev/drbd0 /mnt/drbd
2. Trong /mnt/drbd, tạo cấu trúc lưu trữ dữ liệu của máy chủ web NGINX như sau:
/mnt/drbd/nginx/etc → chứa file cấu hình nginx
/mnt/drbd/nginx/log → chứa log nginx
/mnt/drbd/nginx/html → chứa dữ liệu nội dung website
3. Di chuyển & liên kết trên node1 (primary) và node2 (secondary):
# Backup tất cả dữ liệu và files cấu hình của NGINX của cả 2 nodes( làm trên cả node2), mục đích để chuyển tất cả NGINX data vào DRBD và tạo symlink NGINX từ DRBD trỏ lại về các thư mục chứa dữ liệu và cấu hình của NGINX trong 2 nodes.
sudo mv /etc/nginx /etc/nginx.bak
sudo mv /var/log/nginx /var/log/nginx.bak
sudo mv /var/www/html /var/www/html.bak
# Tạo cấu trúc thư mục mới trên DRBD chỉ làm trên node1.
sudo mkdir -p /mnt/drbd/nginx/etc
sudo mkdir -p /mnt/drbd/nginx/log
sudo mkdir -p /mnt/drbd/nginx/html
# Copy dữ liệu gốc vào DRBD chỉ làm trên node1.
sudo rsync -az /etc/nginx.bak/ /mnt/drbd/nginx/etc/
sudo rsync -az /var/log/nginx.bak/ /mnt/drbd/nginx/log/
sudo rsync -az /var/www/html.bak/ /mnt/drbd/nginx/html/
# Tạo symlink ngược lại làm trên cả node2 để khi failover sang node2, dữ liệu vẫn sẵn sàng bình thường.
sudo ln -s /mnt/drbd/nginx/etc /etc/nginx
sudo ln -s /mnt/drbd/nginx/log /var/log/nginx
sudo ln -s /mnt/drbd/nginx/html /var/www/html
✅ Symlink cần tạo sẵn trên cả node1 và node2 → để khi DRBD failover sẽ được mount trên node2, thì NGINX vẫn biết chính xác nơi lấy cấu hình, log và dữ liệu nội dung web. Như vậy hệ thống vẫn cung cấp dịch vụ web cho người dùng một cách bình thường.
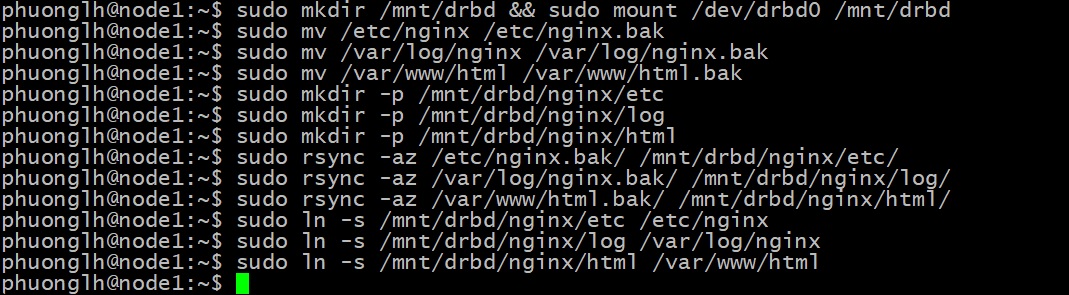
Cuối cùng, unmount DRBD backed file system trên node1:
sudo umount /mnt/drbd
Cấu hình Pacemaker + Corosync trên cả 2 nodes
Cấu hình Corosync
Bạn có thể tìm thấy file cấu hình ví dụ corosync.conf trong phần phụ lục của tài liệu Clusters from Scratch của ClusterLabs. Rất khuyến khích tận dụng tính năng redundant communication rings của Corosync nếu có nhiều hơn một network có tính sẵn sàng cao trong cluster. Để Enable hỗ trợ redundant ring được thực hiện bằng cách thêm tùy chọn rrp_mode và định nghĩa nhiều địa chỉ nodes.
Tạm thời dừng Pacemaker và Corosync để cấu hình cluster membership:
sudo systemctl stop corosync pacemaker
Đổi tên file corosync.conf được tạo trong quá trình cài đặt thành corosync.conf.bak:
sudo mv /etc/corosync/corosync.conf{,.bak}
Tạo và chỉnh sửa file /etc/corosync/corosync.conf, file này sẽ trông tương tự như sau trên cả hai nodes (nhớ thay đổi các địa chỉ IP trong nội dung file theo hệ thống servers của bạn):
totem {
version: 2
secauth: off
cluster_name: cluster
transport: knet
rrp_mode: passive
}
nodelist {
node {
ring0_addr: 10.10.10.1
ring1_addr: 192.168.146.11
nodeid: 1
name: node1
}
node {
ring0_addr: 10.10.10.2
ring1_addr: 192.168.146.12
nodeid: 2
name: node2
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
logging {
to_syslog: yes
}
Bây giờ Corosync đã được cấu hình hãy Khởi động dịch vụ trên cả hai node:
sudo systemctl start corosync pacemaker
sudo crm status. Output sẽ được hiển thị như sau: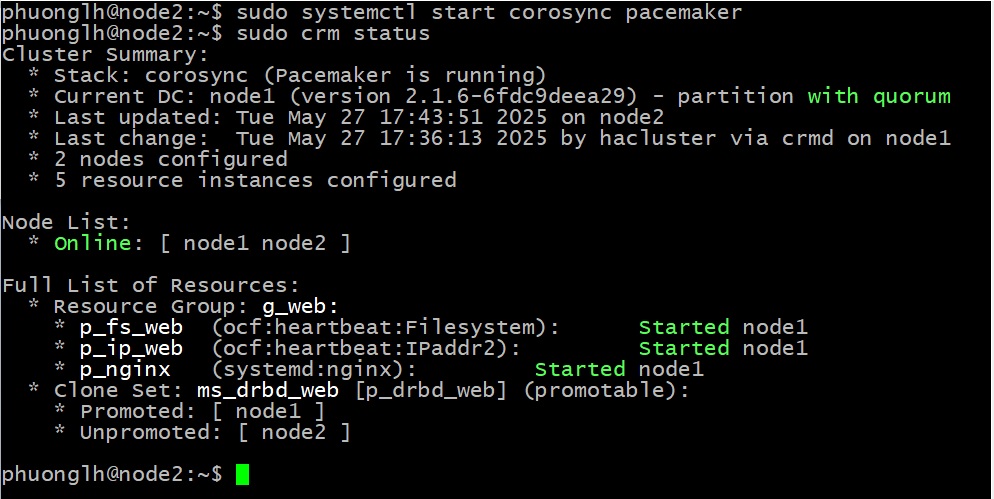
Cấu hình tài nguyên Cluster bằng Pacemaker
Phần này giả định rằng bạn sẽ cấu hình một NGINX Cluster có tính sẵn sàng cao với các tham số cấu hình sau:
- Tài nguyên DRBD hỗ trợ tất cả dữ liệu NGINX ( tất cả các files dữ liệu của NGINX được tải lên) và tương ứng với virtual block device
/dev/drbd0. - DRBD virtual block device (
/dev/drbd0) chứa mộtext4file system sẽ được mounted tại/mnt/drbd. - NGINX sẽ sử dụng file system và máy chủ web sẽ lắng nghe trên địa chỉ IP cluster chuyên dụng với IP là
192.168.146.100. - NGNIX interface được kiểm soát bởi dịch vụ
NGINXservice hiện sẽ được quản lý bởi Pacemaker. Để ngăn dịch vụ này tự động khởi động trong quá trình khởi động, bạn phải tắt dịch vụ này trong systemd.
Chỉ trên một node (ví dụ trên node1) hãy lưu cấu hình sau dưới dạngcib-nginx-ha.txt. Thực hiện các thay đổi cần thiết nào như thay đổi tên node hoặc địa chỉ IP ảo tương ứng với hệ thống servers của bạn:
Trên node1, tạo file cib-nginx-ha.txt với nội dung:
node 1: node1
node 2: node2
primitive p_drbd_web ocf:linbit:drbd \
params drbd_resource=ha \
op start interval=0s timeout=240s \
op stop interval=0s timeout=100s \
op monitor interval=30s role=Promoted \
op monitor interval=32s role=Unpromoted
ms ms_drbd_web p_drbd_web \
meta promoted-max=1 promoted-node-max=1 \
clone-max=2 clone-node-max=1 \
notify=true
primitive p_fs_web ocf:heartbeat:Filesystem \
params device="/dev/drbd0" directory="/mnt/drbd" fstype=ext4 \
op start interval=0s timeout=60s \
op stop interval=0s timeout=60s \
op monitor interval=20s timeout=40s
primitive p_ip_web IPaddr2 \
params ip=192.168.146.100 cidr_netmask=24 \
op start interval=0s timeout=20s \
op stop interval=0s timeout=20s \
op monitor interval=20s timeout=20s
primitive p_nginx systemd:nginx \
op start interval=0s timeout=100s \
op stop interval=0s timeout=100s \
op monitor interval=20s timeout=60s
group g_web p_fs_web p_ip_web p_nginx
colocation c_web_on_drbd inf: g_web ms_drbd_web:Promoted
order o_drbd_before_web ms_drbd_web:promote g_web:start
property cib-bootstrap-options: \
have-watchdog=false \
cluster-infrastructure=corosync \
cluster-name=nginx-ha \
stonith-enabled=false
rsc_defaults rsc-options: \
resource-stickiness=200
Nạp cấu hình vào Pacemaker:
Kích hoạt hệ thống
Sau khi cấu hình xong Khởi động lại Pacemaker trên cả hai nodes một lần cuối:
Sau đó trên node1, bỏ chế độ bảo trì sử dụng lệnh sau:
Sau khi cluster thoát khỏi chế độ bảo trì với cấu hình mới, Pacemaker sẽ:
-
Khởi động DRBD trên cả hai nodes.
- Chọn một node để nâng cấp DRBD từ node Phụ lên node Chính.
-
Mount file system, cấu hình địa chỉ IP cluster và khởi động NGINX server instance trên cùng một node.
-
Bắt đầu giám sát tài nguyên.
✅ Kiểm tra tình trạng hoạt động của cluster sau khi hoàn thành cấu hình
Trên node 1 chạy lệnh sau để xem tình trạng hoạt động của cluster:
Và kiểm tra mount data:
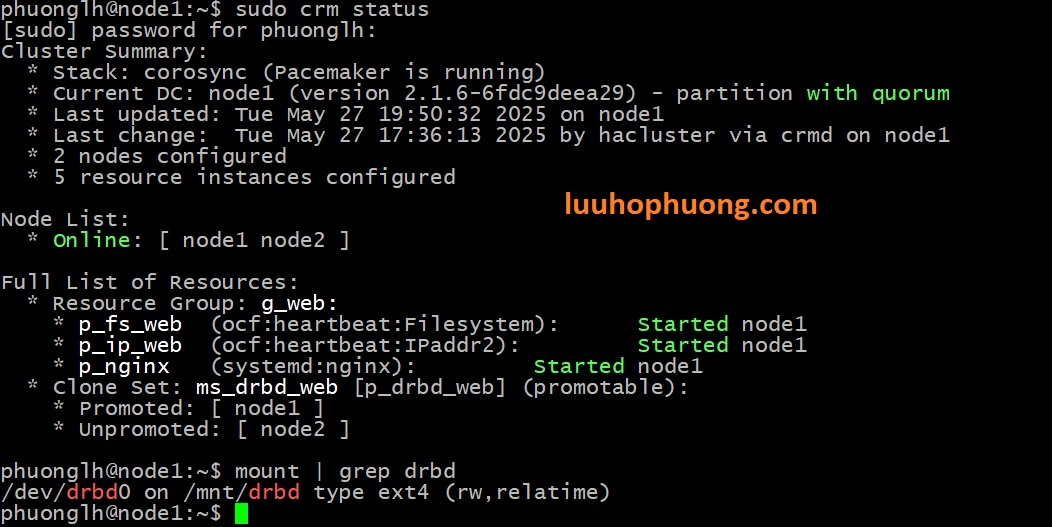
Chạy lệnh này trên node1, để tạo trang web cho demo:
echo "<h1>HA Web from DRBD + NGINX</h1>" | sudo tee /var/www/html/index.html
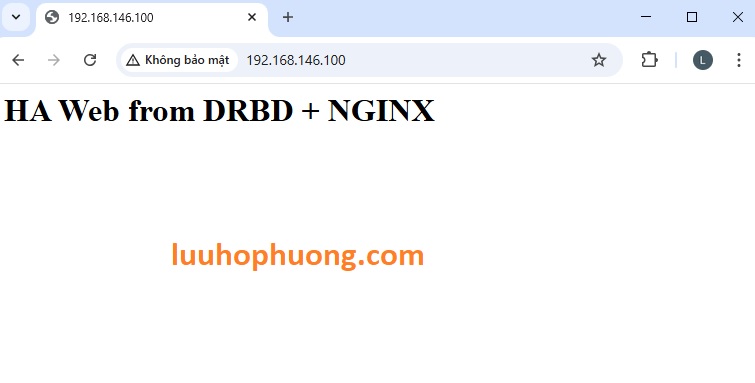
Truy cập trình duyệt với địa chi VIP Cluster:
http://192.168.146.100 → sẽ thấy nội dung test từ NGINX.
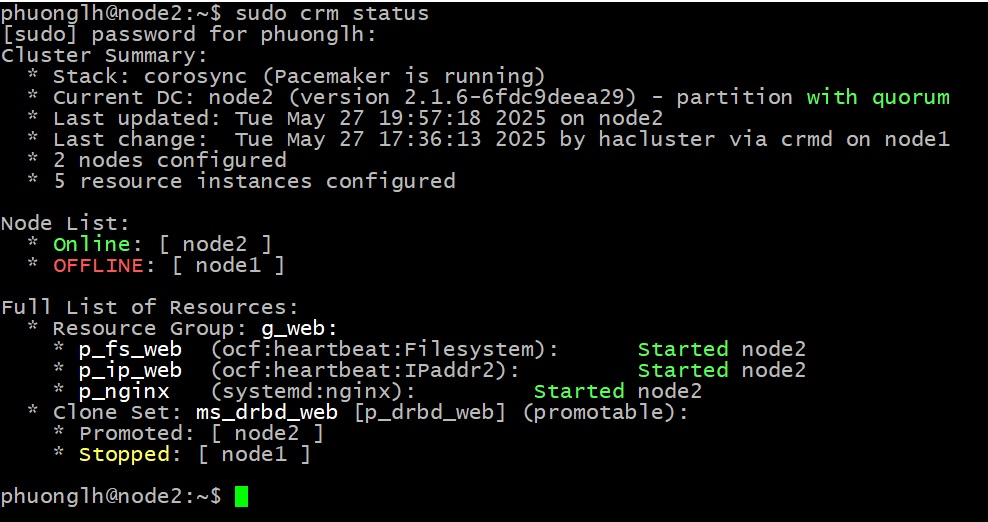
Kiểm thử failover
Giả lập lỗi bằng cách dừng pacemaker trên node1:
Trên node2, kiểm tra:
Bạn sẽ thấy các tài nguyên chuyển sang node2. Truy cập IP ảo vẫn hoạt động bình thường, và vẫn truy cập được vào trang web qua địa chỉ VIP 192.168.146.100 !
Một số lệnh dùng cho troubleshooting.
Để xem toàn bộ cấu hình tài nguyên cấu hình cluster:
sudo crm configure show
Để xem log Pacemaker:
sudo journalctl -u pacemaker -e
Để xem trạng thái và lịch sử của các tài nguyên cluster:
sudo crm resource status Your_resource_name
sudo crm history resource Your_resource_name
VD: sudo crm resource status p_nginx
Để khởi động lại tài nguyên sử dụng lệnh:
sudo crm resource restart Your_resource_name
VD: sudo crm resource restart p_nginx
Để dừng tài nguyên sử dụng lệnh:
sudo crm resource stop Your_resource_name
VD: sudo crm resource stop p_fs_web
Để cleanup toàn bộ toài nguyên cũng như xóa các dấu hiệu lỗi/blocked trước đó nếu có:
sudo crm resource cleanup
Để xóa toàn bộ tài nguyên cấu hình cluster. Đầu tiên tạo một file trống, sau đó load file cấu hình trống:
echo “” > cib-empty.txt
sudo crm configure load replace cib-empty.txt
Sau khi sửa lỗi, bạn phải chạy lệnh sau để xóa trạng thái lỗi trong Pacemaker:
sudo crm resource cleanup p_nginx
IP Ảo: Kiểm tra xem IP ảo Your_VIP (VD:192.168.146.100 )đã được gán cho node hiện tại chưa:
ip a | grep 192.168.146.100
kiểm tra symlink bằng lệnh:
ls -ld /etc/nginx
ls -ld /var/log/nginx
ls -ld /var/www/html
Xem các files ẩn:
ls -la /mnt/drbd/nginx/html
Kiểm tra Cấu Hình NGINX: Sau khi chỉnh sửa, kiểm tra cú pháp cấu hình:
sudo nginx -t
kiểm tra log lỗi của NGINX để tìm hiểu nguyên nhân:
sudo tail -n 50 /var/log/nginx/error.log
sudo journalctl -xeu nginx
✅ Giải pháp: Gỡ hoàn toàn DRBD device cũ và khởi tạo lại, trong trường hợp xác định lỗi không sync được data giữa 2 nodes.
Có thể trường hợp bị DRBD Split-Brain – có nghĩa là 2 node đã từng hoạt động độc lập với dữ liệu trong 2 nodes khác nhau, và giờ DRBD không thể quyết định node nào giữ dữ liệu đúng nên ngắt kết nối tự động để tránh làm hỏng dữ liệu.
Nên kiểm tra log drbd để tìm hiểu trước khi thực hiện các bước dưới sử dụng lệnh sau, trên cả 2 nodes:
sudo journalctl -u drbd -n 50
Tìm các dòng như:
-
Connection refused -
Split-brain -
Cannot resolve hostname…
Bước 0: Dừng mọi tiến trình liên quan (chắc chắn cả DRBD và mount)
Trên cả hai node, chạy lần lượt các lệnh sau:
sudo systemctl stop pacemaker corosync
sudo umount /mnt/drbd 2>/dev/null
sudo drbdadm down ha
Bước 1: Gỡ DRBD device khỏi kernel
Trên cả hai node, chạy lần lượt các lệnh sau:
sudo drbdsetup down /dev/drbd0
sudo modprobe -r drbd
Nếu vẫn lỗi, chạy tiếp lệnh sau:
sudo rm -f /dev/drbd0
Bước 2: Xóa metadata cũ trên disk
Chạy trên cả hai node, lệnh này sẽ xóa cấu hình DRBD cũ trên disk (cẩn trọng với dữ liệu):
sudo drbdadm wipe-md ha
Nếu vẫn báo lỗi, bạn có thể dùng lệnh cưỡng bức:
sudo dd if=/dev/zero of=/dev/sdb1 bs=1M count=10
✅ Bước 3: Tạo lại metadata từ đầu
sudo drbdadm create-md ha
Gõ yes khi được hỏi xác nhận.
Bước 4: Tải lại module và khởi động DRBD
sudo modprobe drbd
sudo drbdadm up ha
Bước 5: Thiết lập lại kết nối
Trên node bạn muốn làm node chính (Primary):
sudo drbdadm primary –force ha
Trên node còn lại, chỉ cần chạy lệnh sau:
sudo drbdadm connect ha
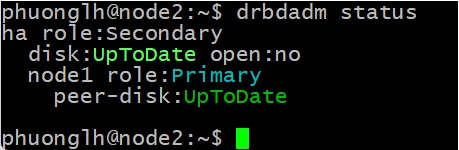
Bước 6: Kiểm tra trạng thái
sudo drbdadm status
Sẽ thấy kết quả trả về:
Các chế độ lỗi
Phần này nói về các chế độ lỗi cụ thể và phản ứng tương ứng của cluster đối với các sự kiện.
Lỗi node
Khi một node cluster gặp sự cố mất điện bất ngờ, cluster sẽ di chuyển tất cả tài nguyên sang node khác.
Trong trường hợp này, Pacemaker di chuyển node bị lỗi từ trạng thái Online sang trạng thái Offline và khởi động các tài nguyên bị ảnh hưởng trên node ngang hàng còn lại.
LƯU Ý: Chi tiết về lỗi node cũng được giải thích trong chương 6 của Hướng dẫn sử dụng DRBD.
Bạn nên giải quyết vấn đề gây ra lỗi node và đưa node trở lại hoạt động bình thường. Thao tác này sẽ đưa cluster trở lại trạng thái hoạt động bình thường.
Lỗi storage
Khi storage sao lưu tài nguyên DRBD bị lỗi trên node Chính, DRBD sẽ tách khỏi thiết bị sao lưu của nó một cách minh bạch và tiếp tục cung cấp dữ liệu qua liên kết sao chép DRBD từ node ngang hàng của nó.
LƯU Ý: Chi tiết về chức năng này được giải thích trong chương 2 của Hướng dẫn sử dụng DRBD.
Bạn nên khắc phục lỗi disk hoặc thay thế disk trên node Chính để đưa cluster trở lại trạng thái hoạt động bình thường.
Lỗi dịch vụ
Trong trường hợp nginx.service bị tắt đột ngột, lỗi phân đoạn hoặc tương tự, hoạt động giám sát cho tài nguyên nginx sẽ phát hiện lỗi và khởi động lại dịch vụ systemd
Kết luận
Cụm HA Cluster sử dụng DRBD + Pacemaker + Corosync + NGINX là một giải pháp hoàn toàn mã nguồn mở, phù hợp với các doanh nghiệp nhỏ giúp tiết kiệm ngân sách đầu tư cho hệ thống IT. Bạn không cần SAN, không cần chi phí cao, chỉ cần hai máy chủ, ổ đĩa riêng và mạng nội bộ tốt là có thể triển khai hệ thống dự phòng thông minh, sẵn sàng phục vụ 24/7.
Sau khi thành thạo mô hình này, bạn có thể mở rộng thêm fencing (STONITH), quorum device hoặc cluster đa nodes để đạt được tính sẵn sàng và ổn định cao hơn cho hệ thống của bạn .
#HACluster #Ubuntu24 #Pacemaker #Corosync #DRBD #NGINX #OpenSource #DoanhNghiepNho #HighAvailability #Failover #LinuxAdmin #SysAdminLife


